1 Active Record クエリインターフェースとは何ですか?
データベースレコードを検索するために生のSQLを使用することに慣れている場合、Railsでは同じ操作をより良い方法で実行できることが一般的にわかるでしょう。Active Recordは、ほとんどの場合においてSQLの使用を必要としないようにします。
Active Recordは、データベース上でクエリを実行し、MySQL、MariaDB、PostgreSQL、SQLiteを含むほとんどのデータベースシステムと互換性があります。どのデータベースシステムを使用しているかに関係なく、Active Recordのメソッド形式は常に同じです。
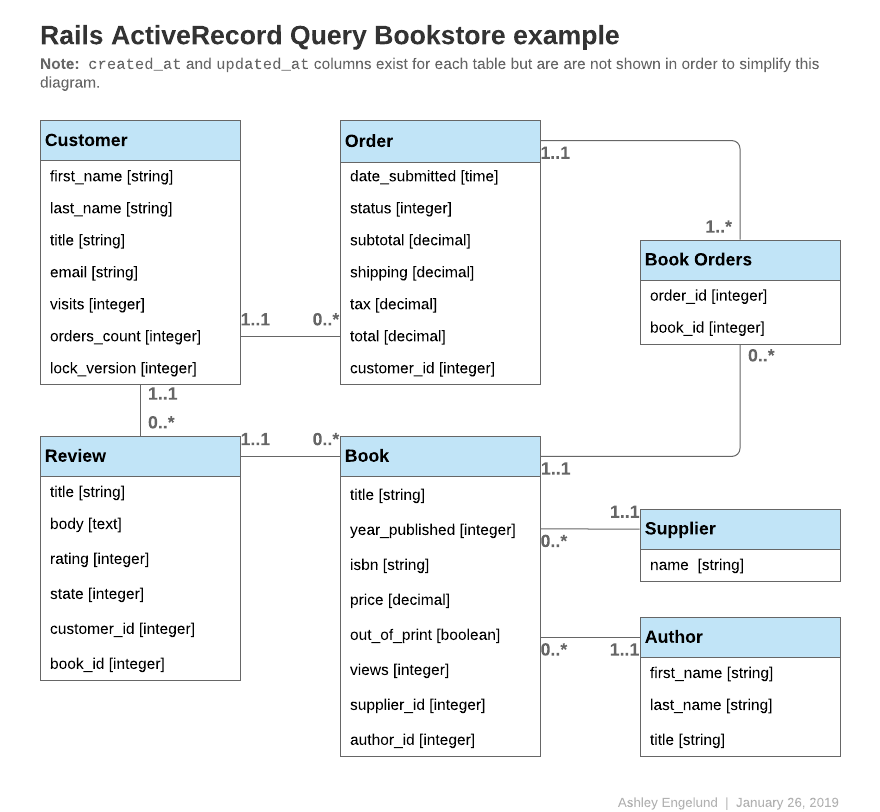
このガイドのコード例では、次のモデルのいずれかを参照します。
ヒント: 以下のすべてのモデルは、指定がない限り、idを主キーとして使用します。
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where(created_at: ...time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
2 データベースからオブジェクトを取得する
データベースからオブジェクトを取得するために、Active Recordはいくつかの検索メソッドを提供しています。各検索メソッドでは、生のSQLを書かずにデータベース上で特定のクエリを実行するための引数を渡すことができます。
以下のメソッドがあります。
annotatefindcreate_withdistincteager_loadextendingextract_associatedfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetoptimizer_hintsorderpreloadreadonlyreferencesreorderreselectregroupreverse_orderselectwhere
whereやgroupなどのコレクションを返す検索メソッドは、ActiveRecord::Relationのインスタンスを返します。findやfirstなどの単一のエンティティを見つけるメソッドは、モデルの単一のインスタンスを返します。
Model.find(options)の主な操作は次のように要約できます。
- 指定されたオプションを等価なSQLクエリに変換します。
- SQLクエリを実行し、データベースから対応する結果を取得します。
- 各結果の行に対応する適切なモデルのRubyオブジェクトをインスタンス化します。
- 必要に応じて、
after_find、after_initializeのコールバックを実行します。
2.1 単一のオブジェクトの取得
Active Recordでは、単一のオブジェクトを取得するためのさまざまな方法が提供されています。
2.1.1 find
findメソッドを使用すると、指定されたオプションに一致する指定された主キーに対応するオブジェクトを取得できます。たとえば:
# 主キー(id)が10の顧客を検索します。
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
上記のSQLの同等のものは次のとおりです。
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
findメソッドは、一致するレコードが見つからない場合にはActiveRecord::RecordNotFound例外を発生させます。
このメソッドを使用して複数のオブジェクトをクエリすることもできます。findメソッドを呼び出し、主キーの配列を渡します。返されるのは、指定された主キーに一致するすべてのレコードを含む配列です。たとえば:
```irb
プライマリキーが1と10の顧客を検索します。
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#
上記のSQLの同等は次の通りです:
SELECT * FROM customers WHERE (customers.id IN (1,10))
警告:findメソッドは、指定されたすべてのプライマリキーに対して一致するレコードが見つからない場合、ActiveRecord::RecordNotFound例外が発生します。
2.1.2 take
takeメソッドは、暗黙の順序付けなしでレコードを取得します。例えば:
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
上記のSQLの同等は次の通りです:
SELECT * FROM customers LIMIT 1
takeメソッドは、レコードが見つからない場合にはnilを返し、例外は発生しません。
takeメソッドに数値の引数を渡すことで、その数までの結果を返すことができます。例えば
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
上記のSQLの同等は次の通りです:
SELECT * FROM customers LIMIT 2
take!メソッドは、takeとまったく同じように動作しますが、一致するレコードが見つからない場合にはActiveRecord::RecordNotFoundを発生させます。
取得されるレコードは、データベースエンジンによって異なる場合があります。
2.1.3 first
firstメソッドは、プライマリキー(デフォルト)で順序付けられた最初のレコードを検索します。例えば:
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
上記のSQLの同等は次の通りです:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
firstメソッドは、一致するレコードが見つからない場合にはnilを返し、例外は発生しません。
デフォルトスコープにorderメソッドが含まれている場合、firstはこの順序に従って最初のレコードを返します。
firstメソッドに数値の引数を渡すことで、その数までの結果を返すことができます。例えば
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
上記のSQLの同等は次の通りです:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
orderを使用して順序付けされたコレクションでは、firstはorderの指定された属性に従って最初のレコードを返します。
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
上記のSQLの同等は次の通りです:
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
first!メソッドは、firstとまったく同じように動作しますが、一致するレコードが見つからない場合にはActiveRecord::RecordNotFoundを発生させます。
2.1.4 last
lastメソッドは、プライマリキー(デフォルト)で順序付けられた最後のレコードを検索します。例えば:
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
上記のSQLの同等は次の通りです:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
lastメソッドは、一致するレコードが見つからない場合にはnilを返し、例外は発生しません。
デフォルトスコープにorderメソッドが含まれている場合、lastはこの順序に従って最後のレコードを返します。
lastメソッドに数値の引数を渡すことで、その数までの結果を返すことができます。例えば
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
上記のSQLの同等は次の通りです:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
orderを使用して順序付けされたコレクションでは、lastはorderの指定された属性に従って最後のレコードを返します。
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
上記のSQLの同等は次の通りです:
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
last!メソッドは、lastとまったく同じように動作しますが、一致するレコードが見つからない場合にはActiveRecord::RecordNotFoundを発生させます。
2.1.5 find_by
find_byメソッドは、条件に一致する最初のレコードを検索します。例えば:
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
これは次のように書くことと同じです:
Customer.where(first_name: 'Lifo').take
上記のSQLの同等は次の通りです:
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
上記のSQLにはORDER BYがありません。find_byの条件が複数のレコードに一致する場合、確定的な結果を保証するために順序を適用する必要があります。
find_by!メソッドは、find_byとまったく同じように動作しますが、一致するレコードが見つからない場合にActiveRecord::RecordNotFoundを発生させます。例:
irb> Customer.find_by! first_name: '存在しない'
ActiveRecord::RecordNotFound
これは次のように書くのと同じです:
Customer.where(first_name: '存在しない').take!
2.2 バッチで複数のオブジェクトを取得する
大量のレコードを反復処理する必要がある場合、例えば大量の顧客にニュースレターを送信する場合やデータをエクスポートする場合など、次のようになります。
# テーブルが大きい場合、これはメモリを多く消費する可能性があります。
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
しかし、このアプローチはテーブルのサイズが増えるにつれてますます実用的ではありません。なぜなら、Customer.all.eachはActive Recordに対してテーブル全体を一度に取得し、1行ごとにモデルオブジェクトを構築し、そしてモデルオブジェクトの配列全体をメモリに保持するからです。実際、大量のレコードがある場合、全体のコレクションは利用可能なメモリ量を超える可能性があります。
Railsは、この問題に対処するために、レコードをメモリに優しいバッチに分割して処理する2つのメソッドを提供しています。最初のメソッドであるfind_eachは、レコードをバッチで取得し、それぞれのレコードをモデルとしてブロックに個別に渡します。2番目のメソッドであるfind_in_batchesは、レコードをバッチで取得し、そのバッチ全体をモデルの配列としてブロックに渡します。
find_eachとfind_in_batchesメソッドは、一度にすべてのレコードをメモリに収めることができない大量のレコードのバッチ処理に使用することを意図しています。千件のレコードをループするだけの場合は、通常の検索メソッドが選択肢として好ましいです。
2.2.1 find_each
find_eachメソッドは、レコードをバッチで取得し、それぞれのレコードをブロックに個別に渡します。次の例では、find_eachが1000件ずつのバッチで顧客を取得し、それぞれを個別にブロックに渡します:
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
このプロセスは、必要に応じてさらにバッチを取得し、すべてのレコードが処理されるまで繰り返されます。
find_eachは、上記のようにモデルクラスで動作するだけでなく、リレーションでも動作します:
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
ただし、順序がない場合に限ります。なぜなら、メソッドが内部的に順序を強制する必要があるためです。
レシーバに順序が存在する場合、動作はconfig.active_record.error_on_ignored_orderフラグに依存します。trueの場合、ArgumentErrorが発生し、それ以外の場合は順序が無視され、警告が発生します(デフォルト)。これは、以下で説明するオプション:error_on_ignoreでオーバーライドできます。
2.2.1.1 find_eachのオプション
:batch_size
:batch_sizeオプションを使用すると、ブロックに個別に渡される前に、各バッチで取得するレコードの数を指定できます。たとえば、5000件ずつのバッチでレコードを取得する場合:
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
デフォルトでは、レコードはプライマリキーの昇順で取得されます。:startオプションを使用すると、最も低いIDが必要なものではない場合に、シーケンスの最初のIDを設定できます。これは、例えば、中断されたバッチ処理を再開する場合に便利です。最後に処理されたIDをチェックポイントとして保存している場合です。
たとえば、プライマリキーが2000から始まる顧客にのみニュースレターを送信する場合:
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
startオプションと同様に、:finishを使用すると、最も高いIDが必要なものではない場合に、シーケンスの最後のIDを設定できます。これは、たとえば、startとfinishに基づいてレコードのサブセットを使用してバッチ処理を実行したい場合に便利です。
たとえば、プライマリキーが2000から10000までの顧客にのみニュースレターを送信する場合:
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
別の例として、同じ処理キューを処理する複数のワーカーを使用したい場合があります。各ワーカーが10000件のレコードを処理するように、各ワーカーに適切なstartとfinishオプションを設定することができます。
:error_on_ignore
関連で順序が存在する場合にエラーが発生するかどうかを指定するために、アプリケーションの設定をオーバーライドします。
:order
プライマリキーの順序を指定します(:ascまたは:desc)。デフォルトは:ascです。
ruby
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
2.2.2 find_in_batches
find_in_batchesメソッドは、find_eachと似ていますが、レコードのバッチを取得する点が異なります。find_in_batchesは、個々ではなく、モデルの配列としてブロックにバッチを渡します。次の例では、最大1000件の顧客を一度にブロックに渡し、最後のブロックには残りの顧客が含まれます。
# 1000件ずつの顧客の配列をadd_customersに渡す
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batchesは、上記のようにモデルクラスで動作しますが、リレーションでも動作します。
# 最近アクティブな顧客を1000件ずつの配列でadd_customersに渡す
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
ただし、順序がない場合は使用できません。なぜなら、メソッドが内部的に順序を強制する必要があるためです。
2.2.2.1 find_in_batchesのオプション
find_in_batchesメソッドは、find_eachと同じオプションを受け入れます。
:batch_size
find_eachと同様に、batch_sizeはグループごとに取得するレコードの数を指定します。たとえば、2500件のレコードのバッチを取得する場合は、次のように指定できます。
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
startオプションを使用すると、選択されるレコードの開始IDを指定できます。前述のように、デフォルトではレコードはプライマリキーの昇順で取得されます。たとえば、ID: 5000から始まる顧客を2500件ずつのバッチで取得する場合は、次のコードを使用できます。
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
finishオプションを使用すると、取得するレコードの終了IDを指定できます。以下のコードは、ID: 7000までの顧客をバッチで取得する例です。
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
error_on_ignoreオプションは、関連に特定の順序が存在する場合にエラーを発生させるかどうかを指定するために、アプリケーションの設定をオーバーライドします。
3 条件
whereメソッドを使用すると、返されるレコードを制限するための条件を指定できます。これはSQLステートメントのWHERE部分を表します。条件は文字列、配列、またはハッシュのいずれかで指定できます。
3.1 純粋な文字列の条件
条件を追加する場合は、Book.where("title = 'Introduction to Algorithms'")のように指定することができます。これにより、titleフィールドの値が「Introduction to Algorithms」であるすべての書籍が検索されます。
警告: 純粋な文字列として自分で条件を構築すると、SQLインジェクションの脆弱性にさらされる可能性があります。たとえば、Book.where("title LIKE '%#{params[:title]}%'")は安全ではありません。条件を扱うための推奨される方法については、次のセクションを参照してください。
3.2 配列の条件
では、タイトルが変動する場合、例えばどこかからの引数として渡される場合はどうなるでしょうか?その場合、検索は次のようになります。
Book.where("title = ?", params[:title])
Active Recordは、最初の引数を条件文字列として受け取り、追加の引数はそれに含まれる疑問符「(?)」を置き換えます。
複数の条件を指定する場合は、次のようにします。
Book.where("title = ? AND out_of_print = ?", params[:title], false)
この例では、最初の疑問符はparams[:title]の値で置き換えられ、2番目の疑問符はアダプタに依存するfalseのSQL表現で置き換えられます。
次のコードは非常に好ましいです。
Book.where("title = ?", params[:title])
次のコードは好ましくありません。
Book.where("title = #{params[:title]}")
なぜなら、引数の安全性が異なるからです。変数を直接条件文字列に入れると、変数がデータベースにそのまま渡されます。つまり、悪意のある意図を持つユーザーからのエスケープされていない変数が直接データベースに渡されることを意味します。これにより、ユーザーがデータベースを悪用できることがわかると、データベース全体が危険にさらされます。引数を直接条件文字列に入れないでください。
SQLインジェクションの危険性についての詳細は、Ruby on Railsセキュリティガイドを参照してください。
3.2.1 プレースホルダー条件
パラメータの(?)の置換スタイルと同様に、条件文字列にキーと対応するキー/値のハッシュを指定することもできます。
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
これにより、変数の条件が多数ある場合に読みやすくなります。
3.2.2 LIKEを使用する条件
条件引数は自動的にエスケープされてSQLインジェクションを防止しますが、SQLのLIKEワイルドカード(つまり、%と_)はエスケープされません。これは、未検証の値が引数に使用される場合に予期しない動作を引き起こす可能性があります。たとえば:
ruby
Book.order(:created_at).order(:title)
This will generate SQL like this:
SELECT * FROM books ORDER BY books.created_at ASC, books.title ASC
You can also use the reorder method to replace any existing order with a new one:
Book.order(:created_at).reorder(:title)
This will generate SQL like this:
SELECT * FROM books ORDER BY books.title ASC
3.3 Limit and Offset
To limit the number of records returned from the database, you can use the limit method. For example, to retrieve the first 5 books:
Book.limit(5)
This will generate SQL like this:
SELECT * FROM books LIMIT 5
To skip a certain number of records and retrieve the rest, you can use the offset method. For example, to skip the first 5 books and retrieve the next 5:
Book.offset(5).limit(5)
This will generate SQL like this:
SELECT * FROM books OFFSET 5 LIMIT 5
You can also chain the limit and offset methods together:
Book.limit(5).offset(5)
This will generate the same SQL as the previous example.
3.4 Grouping
To group records together based on a specific attribute, you can use the group method. For example, to group books by their author:
Book.group(:author)
This will generate SQL like this:
SELECT * FROM books GROUP BY books.author
You can also group by multiple attributes:
Book.group(:author, :category)
This will generate SQL like this:
SELECT * FROM books GROUP BY books.author, books.category
3.5 Having
To filter the grouped records based on a condition, you can use the having method. For example, to find authors who have written more than 5 books:
Book.group(:author).having("COUNT(*) > 5")
This will generate SQL like this:
SELECT * FROM books GROUP BY books.author HAVING COUNT(*) > 5
You can also use the having method with named placeholders:
Book.group(:author).having("COUNT(*) > :count", count: 5)
This will generate the same SQL as the previous example.
3.6 Selecting Specific Fields
By default, Active Record will retrieve all columns from the table when querying records. However, you can specify specific fields to retrieve using the select method. For example, to retrieve only the title and author fields:
Book.select(:title, :author)
This will generate SQL like this:
SELECT books.title, books.author FROM books
You can also use SQL expressions in the select method:
Book.select("title, author, COUNT(*) as book_count").group(:author)
This will generate SQL like this:
SELECT title, author, COUNT(*) as book_count FROM books GROUP BY books.author
3.7 Joins
To perform a SQL join between two tables, you can use the joins method. For example, to retrieve all books with their associated authors:
Book.joins(:author)
This will generate SQL like this:
SELECT * FROM books INNER JOIN authors ON authors.id = books.author_id
You can also specify the type of join to perform:
Book.joins("LEFT OUTER JOIN authors ON authors.id = books.author_id")
This will generate SQL like this:
SELECT * FROM books LEFT OUTER JOIN authors ON authors.id = books.author_id
3.8 Eager Loading
By default, when you retrieve records with associations, Active Record will perform a separate query for each association. This can lead to the N+1 query problem, where the number of queries grows linearly with the number of records retrieved.
To avoid this problem, you can use the includes method to eager load associations. For example, to retrieve all books with their associated authors in a single query:
Book.includes(:author)
This will generate SQL like this:
SELECT * FROM books LEFT OUTER JOIN authors ON authors.id = books.author_id
You can also specify multiple associations to eager load:
Book.includes(:author, :category)
This will generate SQL like this:
SELECT * FROM books LEFT OUTER JOIN authors ON authors.id = books.author_id LEFT OUTER JOIN categories ON categories.id = books.category_id
3.9 Locking
To lock records in the database to prevent other transactions from modifying them, you can use the lock method. For example, to lock a book record:
Book.find(1).lock!
This will generate SQL like this:
SELECT * FROM books WHERE books.id = 1 FOR UPDATE
You can also use the lock method with a block to lock multiple records:
Book.lock do
Book.where(out_of_print: true).update_all(sold_out: true)
end
This will generate SQL like this:
SELECT * FROM books WHERE books.out_of_print = 1 FOR UPDATE
UPDATE books SET sold_out = 1 WHERE books.out_of_print = 1
3.10 Transactions
To perform a series of database operations as a single atomic unit, you can use the [transaction][] method. For example, to transfer funds between two bank accounts:
Account.transaction do
sender = Account.find(1)
receiver = Account.find(2)
sender.balance -= 100
receiver.balance += 100
sender.save!
receiver.save!
end
If an exception is raised within the transaction block, the transaction will be rolled back and no changes will be made to the database.
3.11 Raw SQL Queries
If you need to execute a raw SQL query, you can use the find_by_sql method. For example, to retrieve all books with a rating greater than 4:
Book.find_by_sql("SELECT * FROM books WHERE rating > 4")
This will return an array of Book objects.
You can also use the [execute][] method to execute a raw SQL query and return the result as a PG::Result object:
result = ActiveRecord::Base.connection.execute("SELECT * FROM books WHERE rating > 4")
result.each do |row|
# process row
end
3.12 Conclusion
Active Record provides a powerful and flexible interface for querying and manipulating databases. By understanding the various methods and techniques available, you can write efficient and expressive database queries in your Ruby applications.
irb
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
警告:ほとんどのデータベースシステムでは、select、pluck、idsなどのメソッドを使用して結果セットからdistinctを持つフィールドを選択する場合、orderメソッドは、order句で使用されるフィールドが選択リストに含まれていない限り、ActiveRecord::StatementInvalid例外を発生させます。結果セットからフィールドを選択する方法については、次のセクションを参照してください。
4 特定のフィールドの選択
デフォルトでは、Model.findはselect *を使用して結果セットからすべてのフィールドを選択します。
結果セットからのフィールドのサブセットのみを選択するには、selectメソッドを使用してサブセットを指定できます。
例えば、isbnとout_of_printの列のみを選択する場合は:
Book.select(:isbn, :out_of_print)
# または
Book.select("isbn, out_of_print")
このfind呼び出しで使用されるSQLクエリは、次のようなものになります:
SELECT isbn, out_of_print FROM books
注意が必要ですが、これは選択したフィールドのみでモデルオブジェクトを初期化することを意味します。初期化されたレコードに存在しないフィールドにアクセスしようとすると、次のエラーが発生します:
ActiveModel::MissingAttributeError: missing attribute '<attribute>' for Book
ここで、<attribute>は要求した属性です。idメソッドはActiveRecord::MissingAttributeErrorを発生させませんので、関連付けと一緒に作業する場合は注意してください。関連付けにはidメソッドが正しく機能する必要があります。
特定のフィールドの一意の値ごとに1つのレコードのみを取得したい場合は、distinctを使用できます:
Customer.select(:last_name).distinct
これにより、次のようなSQLが生成されます:
SELECT DISTINCT last_name FROM customers
一意性の制約を解除することもできます:
# 一意のlast_nameを返す
query = Customer.select(:last_name).distinct
# 重複がある場合でもすべてのlast_nameを返す
query.distinct(false)
5 制限とオフセット
Model.findによって発行されるSQLにLIMITを適用するには、関連のlimitおよびoffsetメソッドを使用してLIMITを指定できます。
limitを使用して取得するレコードの数を指定し、offsetを使用してレコードを返す前にスキップするレコードの数を指定できます。例えば
Customer.limit(5)
これにより、最大5人の顧客が返されます。オフセットが指定されていないため、テーブルの最初の5人が返されます。実行されるSQLは次のようになります:
SELECT * FROM customers LIMIT 5
それにoffsetを追加すると
Customer.limit(5).offset(30)
これにより、31番目から始まる最大5人の顧客が返されます。SQLは次のようになります:
SELECT * FROM customers LIMIT 5 OFFSET 30
6 グループ化
ファインダーによって発行されるSQLにGROUP BY句を適用するには、groupメソッドを使用できます。
例えば、注文が作成された日付のコレクションを見つけたい場合は:
Order.select("created_at").group("created_at")
これにより、データベースに注文がある日付ごとに1つのOrderオブジェクトが返されます。
実行されるSQLは次のようなものになります:
SELECT created_at
FROM orders
GROUP BY created_at
6.1 グループ化されたアイテムの合計
単一のクエリでグループ化されたアイテムの合計を取得するには、groupの後にcountを呼び出します。
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
実行されるSQLは次のようなものになります:
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
6.2 HAVING条件
SQLでは、HAVING句を使用してGROUP BYフィールドに条件を指定します。havingメソッドをfindに追加することで、Model.findによって発行されるSQLにHAVING句を追加できます。
例えば:
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
実行されるSQLは次のようなものになります:
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
これにより、注文が行われた日付ごとに、注文が$200を超える合計金額と日付が返されます。
返された各注文オブジェクトのtotal_priceには次のようにアクセスします:
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# 最初のOrderオブジェクトの合計金額を返します
7 条件のオーバーライド
7.1 unscope
unscopeメソッドを使用して、特定の条件を削除することができます。例えば:
ruby
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
実行されるSQL:
SELECT * FROM books WHERE id > 100 LIMIT 20
-- `unscope`なしの元のクエリ
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
また、特定のwhere句を削除することもできます。例えば、次のようにするとid条件が削除されます:
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
unscopeを使用したリレーションは、マージされるリレーションに影響を与えます:
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
7.2 only
onlyメソッドを使用して条件を上書きすることもできます。例えば:
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
実行されるSQL:
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- `only`なしの元のクエリ
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
7.3 reselect
reselectメソッドは既存のselect文を上書きします。例えば:
Book.select(:title, :isbn).reselect(:created_at)
実行されるSQL:
SELECT books.created_at FROM books
これはreselect句を使用しない場合と比較してください:
Book.select(:title, :isbn).select(:created_at)
実行されるSQL:
SELECT books.title, books.isbn, books.created_at FROM books
7.4 reorder
reorderメソッドはデフォルトのスコープ順序を上書きします。例えば、クラス定義に次のようなものが含まれている場合:
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
そして、次のように実行すると:
Author.find(10).books
実行されるSQL:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
reorder句を使用して異なる方法で本を並べ替えることができます:
Author.find(10).books.reorder('year_published ASC')
実行されるSQL:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
7.5 reverse_order
reverse_orderメソッドは指定された場合に順序句を逆にします。
Book.where("author_id > 10").order(:year_published).reverse_order
実行されるSQL:
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
クエリで順序句が指定されていない場合、reverse_orderは主キーで逆順に並べ替えます。
Book.where("author_id > 10").reverse_order
実行されるSQL:
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
reverse_orderメソッドは引数を受け取りません。
7.6 rewhere
[rewhere][]メソッドは既存の名前付きwhere条件を上書きします。例えば:
Book.where(out_of_print: true).rewhere(out_of_print: false)
実行されるSQL:
SELECT * FROM books WHERE out_of_print = 0
rewhere句を使用しない場合、where句はANDで結合されます:
Book.where(out_of_print: true).where(out_of_print: false)
実行されるSQL:
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
7.7 regroup
regroupメソッドは既存の名前付きgroup条件を上書きします。例えば:
Book.group(:author).regroup(:id)
実行されるSQL:
SELECT * FROM books GROUP BY id
regroup句を使用しない場合、group句は結合されます:
Book.group(:author).group(:id)
実行されるSQL:
SELECT * FROM books GROUP BY author, id
8 Null Relation
noneメソッドは、レコードがないチェーン可能なリレーションを返します。返されたリレーションにチェーンされる後続の条件は、空のリレーションを生成し続けます。これは、メソッドやスコープがゼロの結果を返す可能性がある場合に、チェーン可能な応答が必要なシナリオで便利です。
Book.none # 空のRelationを返し、クエリを実行しません。
# 以下のhighlighted_reviewsメソッドは常にRelationを返すことが期待されています。
Book.first.highlighted_reviews.average(:rating)
# => 本の平均評価を返します
class Book
# レビューが5つ以上ある場合はレビューを返し、
# それ以外の場合はまだ最低限の条件を満たしていないと見なされます。
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # 最低限の閾値を満たしていません
end
end
end
9 Readonly Objects
Active Recordは、返されたオブジェクトの変更を明示的に禁止するために、リレーションにreadonlyメソッドを提供します。読み取り専用レコードを変更しようとする試みは成功せず、ActiveRecord::ReadOnlyRecord例外が発生します。
ruby
customer = Customer.readonly.first
customer.visits += 1
customer.save
上記のコードでは、customer が明示的に読み取り専用オブジェクトに設定されているため、customer.save を呼び出して visits の値を更新すると、ActiveRecord::ReadOnlyRecord 例外が発生します。
10 レコードのロック
ロックは、データベース内のレコードを更新する際の競合状態を防ぐために役立ち、アトミックな更新を保証します。
Active Record には、2つのロックメカニズムが用意されています。
- 楽観的ロック
- 悲観的ロック
10.1 楽観的ロック
楽観的ロックは、複数のユーザーが同じレコードにアクセスして編集することができ、データとの競合が最小限であると想定しています。これは、レコードが開かれてから他のプロセスが変更を加えたかどうかをチェックすることで実現されます。もし変更があった場合、ActiveRecord::StaleObjectError 例外がスローされ、更新は無視されます。
楽観的ロックカラム
楽観的ロックを使用するためには、テーブルに lock_version という名前の整数型のカラムが必要です。レコードが更新されるたびに、Active Record は lock_version カラムをインクリメントします。もし更新リクエストが、データベースの lock_version カラムに現在の値よりも低い値を持つ lock_version フィールドで行われた場合、更新リクエストは ActiveRecord::StaleObjectError で失敗します。
例:
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # ActiveRecord::StaleObjectError が発生する
その後、例外をキャッチして競合を解決するために、ロールバック、マージ、またはその他のビジネスロジックを適用する責任があります。
この動作は、ActiveRecord::Base.lock_optimistically = false と設定することで無効にすることができます。
lock_version カラムの名前をオーバーライドするには、ActiveRecord::Base は locking_column というクラス属性を提供しています。
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
10.2 悲観的ロック
悲観的ロックは、基礎となるデータベースが提供するロックメカニズムを使用します。lock を使用してリレーションを構築すると、選択された行に排他的なロックが取得されます。通常、lock を使用するリレーションはデッドロック状態を防ぐためにトランザクションでラップされます。
例:
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, second edition'
book.save!
end
上記のセッションは、MySQL バックエンドの場合、次の SQL を生成します:
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, second edition' WHERE id = 1
SQL (0.8ms) COMMIT
lock メソッドに対して生の SQL を渡すことで、異なる種類のロックを許可することもできます。たとえば、MySQL には LOCK IN SHARE MODE という式があり、レコードをロックするが他のクエリから読み取りを許可することができます。この式を指定するには、ロックオプションとして渡します:
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
注意: データベースが lock メソッドに渡される生の SQL をサポートしている必要があります。
モデルのインスタンスが既にある場合、次のコードを使用してトランザクションを開始し、ロックを一度に取得することもできます:
book = Book.first
book.with_lock do
# このブロックはトランザクション内で呼び出されます
# book は既にロックされています
book.increment!(:views)
end
11 テーブルの結合
Active Record は、結果の SQL に JOIN 句を指定するための2つの検索メソッドを提供しています: joins と left_outer_joins。
joins は INNER JOIN やカスタムクエリに使用され、left_outer_joins は LEFT OUTER JOIN を使用するクエリに使用されます。
11.1 joins
joins メソッドの使用方法は複数あります。
11.1.1 文字列の SQL フラグメントを使用する
joins に JOIN 句を指定する生の SQL を単純に渡すことができます:
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
これにより、次の SQL が生成されます:
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
11.1.2 名前付き関連の配列/ハッシュを使用する
Active Record では、joins メソッドを使用する際に、モデルで定義された 関連 の名前を使用して JOIN 句を指定するショートカットとして使用することができます。
次のいずれかを使用すると、INNER JOIN を使用した期待どおりの結合クエリが生成されます:
11.1.2.1 単一の関連の結合
Book.joins(:reviews)
これにより、次の SQL が生成されます:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
または、日本語で言うと「レビューのあるすべての本の Book オブジェクトを返す」となります。同じ本に複数のレビューがある場合、重複した本が表示されます。一意の本を表示したい場合は、Book.joins(:reviews).distinct を使用できます。
11.1.3 複数の関連を結合する
Book.joins(:author, :reviews)
これにより以下が生成されます:
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
または、英語では「少なくとも1つのレビューを持つ著者と共にすべての本を返す」となります。なお、複数のレビューを持つ本は複数回表示されます。
11.1.3.1 ネストされた関連の結合(単一レベル)
Book.joins(reviews: :customer)
これにより以下が生成されます:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
または、英語では「顧客によるレビューを持つすべての本を返す」となります。
11.1.3.2 ネストされた関連の結合(複数レベル)
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier])
これにより以下が生成されます:
SELECT * FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
または、英語では「レビューを持つ本を持つすべての著者を返し、顧客によって注文された本のサプライヤーを返す」となります。
11.1.4 結合テーブルに条件を指定する
通常の配列条件と文字列条件を使用して、結合テーブルに条件を指定することができます。ハッシュ条件は、結合テーブルの条件を指定するための特別な構文を提供します。
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
これにより、created_atを比較するためにBETWEEN SQL式を使用して、昨日作成された注文を持つすべての顧客が見つかります。
ハッシュ条件をネストすることで、代替できるよりクリーンな構文があります。
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
より高度な条件を指定する場合や、既存の名前付きスコープを再利用する場合は、mergeを使用することができます。まず、Orderモデルに新しい名前付きスコープを追加しましょう。
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
次に、mergeを使用してcreated_in_time_rangeスコープをマージします。
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
これにより、BETWEEN SQL式を使用して昨日作成された注文を持つすべての顧客が見つかります。
11.2 left_outer_joins
関連レコードの有無に関係なく、一連のレコードを選択する場合は、left_outer_joinsメソッドを使用できます。
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
これにより以下が生成されます:
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
つまり、「すべての顧客とそのレビューの数を返すが、レビューがない場合でも返す」となります。
11.3 where.associatedとwhere.missing
associatedとmissingクエリメソッドを使用すると、関連の存在または不在に基づいて一連のレコードを選択することができます。
where.associatedを使用する場合:
Customer.where.associated(:reviews)
これにより以下が生成されます:
SELECT customers.* FROM customers
INNER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NOT NULL
つまり、「少なくとも1つのレビューを作成したすべての顧客を返す」となります。
where.missingを使用する場合:
Customer.where.missing(:reviews)
これにより以下が生成されます:
SELECT customers.* FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NULL
つまり、「レビューを作成していないすべての顧客を返す」となります。
12 関連の一括読み込み
一括読み込みは、Model.findで返されるオブジェクトの関連レコードを可能な限り少ないクエリで読み込むためのメカニズムです。
12.1 N + 1 クエリ問題
次のコードを考えてみましょう。10冊の本を検索し、それぞれの著者の姓を表示します。
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
このコードは最初の見た目では問題ありません。しかし、実行されるクエリの総数に問題があります。上記のコードでは、合計で1回(10冊の本を検索するため)+ 10回(各本ごとに著者を読み込むため)= 11回のクエリが実行されます。
12.1.1 N + 1 クエリ問題への解決策
Active Recordでは、事前に読み込まれるすべての関連を指定することができます。
メソッドは次のとおりです:
12.2 includes
includesを使用すると、Active Recordは指定されたすべての関連を最小限のクエリを使用して読み込むことを保証します。
includesメソッドを使用して上記のケースを再訪し、著者を一括読み込みするようにBook.limit(10)を書き直すことができます。
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上記のコードは、元のケースの11つのクエリに対して、わずか2つのクエリを実行します。
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
12.2.1 複数の関連を一括読み込みする
Active Recordでは、includesメソッドを使用して、配列、ハッシュ、またはネストされた配列/ハッシュを使用して、単一のModel.find呼び出しで任意の数の関連を一括読み込みすることができます。
12.2.1.1 複数の関連の配列
Customer.includes(:orders, :reviews)
これにより、すべての顧客とそれぞれの関連する注文とレビューが読み込まれます。
12.2.1.2 ネストされた関連のハッシュ
Customer.includes(orders: { books: [:supplier, :author] }).find(1)
これにより、idが1の顧客が見つかり、それに関連するすべての注文、注文のすべての書籍、および各書籍の著者とサプライヤーが一括読み込みされます。
12.2.2 一括読み込みされた関連に条件を指定する
Active Recordでは、joinsと同様に、一括読み込みされた関連に条件を指定することができますが、推奨される方法はjoinsを使用することです。
ただし、必要な場合は、通常どおりにwhereを使用することができます。
Author.includes(:books).where(books: { out_of_print: true })
これにより、LEFT OUTER JOINを含むクエリが生成されますが、joinsメソッドは代わりにINNER JOIN関数を使用してクエリを生成します。
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN books ON books.author_id = authors.id WHERE (books.out_of_print = 1)
where条件がない場合、通常の2つのクエリセットが生成されます。
注意:このようにwhereを使用するには、ハッシュを渡す必要があります。SQLフラグメントの場合は、結合されたテーブルを強制するためにreferencesを使用する必要があります。
Author.includes(:books).where("books.out_of_print = true").references(:books)
このincludesクエリの場合、どの著者にも書籍がない場合でも、すべての著者が読み込まれます。joins(INNER JOIN)を使用すると、結合条件が一致しない場合はレコードが返されません。
注意:関連が結合の一部として一括読み込みされる場合、カスタムセレクト句のフィールドは読み込まれたモデルに存在しないため、どのレコードに表示されるべきか、親レコードに表示されるべきか、子レコードに表示されるべきかは曖昧です。
12.3 preload
preloadを使用すると、Active Recordは各指定された関連を1つのクエリごとに読み込みます。
N + 1クエリの問題を再訪し、Book.limit(10)を著者のプリロードに書き換えることができます。
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上記のコードは、元のケースの11つのクエリに対して、わずか2つのクエリを実行します。
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
注意:preloadメソッドは、includesメソッドと同様に、配列、ハッシュ、またはネストされた配列/ハッシュを使用して、単一のModel.find呼び出しで任意の数の関連を一括読み込みするために使用されます。ただし、includesメソッドとは異なり、プリロードされた関連に条件を指定することはできません。
12.4 eager_load
eager_loadを使用すると、Active RecordはLEFT OUTER JOINを使用してすべての指定された関連を読み込みます。
eager_loadメソッドを使用してN + 1が発生した場合のケースを再訪し、Book.limit(10)を著者に書き換えることができます。
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上記のコードは、元のケースの11つのクエリに対して、わずか2つのクエリを実行します。
SELECT DISTINCT books.id FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id LIMIT 10
SELECT books.id AS t0_r0, books.last_name AS t0_r1, ...
FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id
WHERE books.id IN (1,2,3,4,5,6,7,8,9,10)
注意:eager_loadメソッドは、includesメソッドと同様に、配列、ハッシュ、またはネストされた配列/ハッシュを使用して、単一のModel.find呼び出しで任意の数の関連を一括読み込みするために使用されます。また、includesメソッドと同様に、一括読み込みされた関連に条件を指定することもできます。
12.5 strict_loading
一括読み込みはN + 1クエリを防ぐことができますが、まだ一部の関連が遅延読み込みされている可能性があります。すべての関連が遅延読み込みされないようにするには、strict_loadingを有効にすることができます。
関連付けられたレコードが遅延読み込みされようとすると、関連付けられたレコードが遅延読み込みされることを防ぐために、関連付けられたレコードの読み込み中にActiveRecord::StrictLoadingViolationErrorが発生します。
user = User.strict_loading.first
user.comments.to_a # ActiveRecord::StrictLoadingViolationErrorが発生します
13 スコープ
スコープを使用すると、関連オブジェクトやモデルのメソッド呼び出しとして参照できるよく使用されるクエリを指定できます。これらのスコープを使用すると、where、joins、includesなど、以前に説明したすべてのメソッドを使用できます。すべてのスコープの本体は、さらなるメソッド(他のスコープなど)が呼び出されるために、ActiveRecord::Relationまたはnilを返す必要があります。
シンプルなスコープを定義するには、クラス内でscopeメソッドを使用し、このスコープが呼び出されたときに実行するクエリを渡します。
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
このout_of_printスコープを呼び出すには、クラスまたはBookオブジェクトの関連オブジェクトのいずれかで呼び出すことができます。
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # すべての絶版の本
または、Bookオブジェクトの関連オブジェクトである場合:
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # `author`のすべての絶版の本
スコープはスコープ内でもチェーン可能です。
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
13.1 引数の渡し方
スコープに引数を渡すことができます。
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
クラスメソッドとして提供される機能を複製しているだけですが、スコープを呼び出す方法は次のようになります。
irb> Book.costs_more_than(100.10)
ただし、これはクラスメソッドによって提供される機能を複製しているだけです。
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
これらのメソッドは、関連オブジェクトでもアクセスできます。
irb> author.books.costs_more_than(100.10)
13.2 条件付きの使用
スコープでは条件を利用することができます。
class Order < ApplicationRecord
scope :created_before, ->(time) { where(created_at: ...time) if time.present? }
end
他の例と同様に、これはクラスメソッドと同様に動作します。
class Order < ApplicationRecord
def self.created_before(time)
where(created_at: ...time) if time.present?
end
end
ただし、重要な注意点があります。スコープは常にActiveRecord::Relationオブジェクトを返しますが、条件がfalseに評価された場合でも、クラスメソッドはnilを返します。これは、条件付きのクラスメソッドのチェーン時にNoMethodErrorが発生する可能性があることを意味します。
13.3 デフォルトスコープの適用
モデルへのすべてのクエリにスコープを適用したい場合は、モデル自体内でdefault_scopeメソッドを使用できます。
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
このモデルでクエリが実行されると、SQLクエリは次のようになります。
SELECT * FROM books WHERE (out_of_print = false)
デフォルトスコープをより複雑な操作に使用する場合は、代わりにクラスメソッドとして定義することもできます。
class Book < ApplicationRecord
def self.default_scope
# ActiveRecord::Relationを返す必要があります。
end
end
注意:default_scopeは、スコープの引数がHashとして与えられた場合にも、レコードの作成/ビルド時に適用されますが、レコードの更新時には適用されません。例:
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
Array形式で指定された場合、default_scopeクエリ引数はデフォルトの属性割り当てのためにHashに変換できません。例:
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
13.4 スコープのマージ
where句と同様に、スコープはAND条件を使用してマージされます。
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where(year_published: 50.years.ago.year..) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
scopeとwhereの条件を組み合わせることができ、最終的なSQLにはすべての条件がANDで結合されます。
irb> Book.in_print.where(price: ...100)
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
最後のwhere句が優先される場合は、mergeを使用できます。
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
重要な注意点として、default_scopeはscopeとwhereの条件の前に追加されます。
```ruby
class Book < ApplicationRecord
default_scope { where(year_published: 50.years.ago.year..) }
scope :in_print, -> { where(out_of_print: false) } scope :out_of_print, -> { where(out_of_print: true) } end ```
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
上記のように、default_scopeはscopeとwhereの条件にマージされています。
13.5 すべてのスコープを削除する
任意の理由でスコープを削除したい場合は、unscopedメソッドを使用できます。これは、モデルでdefault_scopeが指定されていて、特定のクエリに適用されない場合に特に便利です。
Book.unscoped.load
このメソッドはすべてのスコープを削除し、テーブル上で通常のクエリを実行します。
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscopedはブロックも受け入れることができます。
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
動的なファインダー
各フィールド(属性とも呼ばれる)には、Active Recordがファインダーメソッドを提供します。たとえば、Customerモデルにfirst_nameというフィールドがある場合、Active Recordからfind_by_first_nameというインスタンスメソッドが自動的に提供されます。Customerモデルにlockedフィールドもある場合、find_by_lockedメソッドも提供されます。
動的なファインダーの末尾に感嘆符(!)を付けると、レコードが返されない場合にActiveRecord::RecordNotFoundエラーが発生するようになります。たとえば、Customer.find_by_first_name!("Ryan")のようになります。
first_nameとorders_countの両方で検索する場合は、フィールド間に「and」を入力するだけでこれらのファインダーをチェーンすることができます。たとえば、Customer.find_by_first_name_and_orders_count("Ryan", 5)です。
Enums
Enumを使用すると、属性の値の配列を定義し、名前で参照することができます。データベースに格納される実際の値は、値のいずれかにマップされた整数です。
Enumを宣言すると、次のことが行われます。
- Enumの値を持つまたは持たないすべてのオブジェクトを検索するために使用できるスコープが作成されます。
- Enumの特定の値を持つオブジェクトを判別するために使用できるインスタンスメソッドが作成されます。
- オブジェクトのEnum値を変更するために使用できるインスタンスメソッドが作成されます。
Enumのすべての可能な値に対して。
たとえば、次のenum宣言がある場合:
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
これらのスコープは自動的に作成され、statusに特定の値を持つすべてのオブジェクトを検索するために使用できます。
irb> Order.shipped
=> #<ActiveRecord::Relation> # status == :shippedのすべての注文
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # status != :shippedのすべての注文
これらのインスタンスメソッドは自動的に作成され、モデルがstatus Enumの値を持つかどうかをクエリします。
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
これらのインスタンスメソッドは自動的に作成され、最初にstatusの値を指定された値に更新し、その後、ステータスが指定された値に正常に設定されたかどうかをクエリします。
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
Enumに関する詳細なドキュメントはこちらを参照してください。
メソッドチェーンの理解
Active Recordパターンでは、メソッドチェーンを実装しており、複数のActive Recordメソッドを簡単かつ直感的に組み合わせて使用することができます。
前のメソッド呼び出しがActiveRecord::Relationを返す場合(all、where、joinsなど)、ステートメントでメソッドをチェーンすることができます。単一のオブジェクトを返すメソッド(単一のオブジェクトの取得セクションを参照)は、ステートメントの最後に配置する必要があります。
以下にいくつかの例を示します。このガイドでは、すべての可能性を網羅するわけではありませんが、いくつかの例を示します。Active Recordメソッドが呼び出されると、クエリはすぐに生成されてデータベースに送信されるわけではありません。データが実際に必要なときにのみクエリが送信されます。したがって、以下の例はすべて単一のクエリを生成します。
複数のテーブルからフィルタリングされたデータの取得
ruby
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
結果は次のようになります:
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
13.6 複数のテーブルから特定のデータを取得する
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
上記のコードは次のようになります:
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
注意:クエリが複数のレコードに一致する場合、find_byは最初のレコードのみを取得し、他のレコードは無視します(上記のLIMIT 1ステートメントを参照)。
14 オブジェクトの検索または新規作成
レコードを検索し、存在しない場合は作成する必要がある場合がよくあります。これはfind_or_create_byメソッドとfind_or_create_by!メソッドを使用して行うことができます。
14.1 find_or_create_by
find_or_create_byメソッドは、指定された属性を持つレコードが存在するかどうかをチェックします。存在しない場合はcreateが呼び出されます。以下に例を示します。
「Andy」という名前の顧客を検索し、存在しない場合は作成したいとします。次のように実行することで、それが可能です。
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
このメソッドによって生成されるSQLは次のようになります:
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_byは、既に存在するレコードまたは新しいレコードのいずれかを返します。この場合、Andyという名前の顧客はまだ存在しないため、レコードが作成されて返されます。
新しいレコードはデータベースに保存されない場合もあります。これは、バリデーションが成功したかどうかに依存します(createと同様)。
新しいレコードを作成する場合に「locked」属性をfalseに設定したいが、クエリには含めたくない場合を考えてみましょう。つまり、「Andy」という名前の顧客を検索し、その顧客が存在しない場合はロックされていない「Andy」という名前の顧客を作成したいとします。
これは2つの方法で実現できます。最初の方法は、create_withを使用する方法です:
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
2番目の方法は、ブロックを使用する方法です:
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
このブロックは、顧客が作成されている場合にのみ実行されます。2回目にこのコードを実行すると、ブロックは無視されます。
14.2 find_or_create_by!
find_or_create_by!を使用すると、新しいレコードが無効な場合に例外を発生させることができます。このガイドではバリデーションについては触れませんが、一時的に次のようなバリデーションをCustomerモデルに追加したと仮定しましょう。
validates :orders_count, presence: true
orders_countを指定せずに新しいCustomerを作成しようとすると、レコードが無効になり、例外が発生します:
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can’t be blank
14.3 find_or_initialize_by
find_or_initialize_byメソッドは、find_or_create_byと同様に動作しますが、createの代わりにnewが呼び出されます。つまり、新しいモデルインスタンスがメモリ上に作成されますが、データベースには保存されません。find_or_create_byの例を続けて、'Nina'という名前の顧客を作成したいとします。
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
オブジェクトがまだデータベースに保存されていないため、生成されるSQLは次のようになります:
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
データベースに保存する場合は、saveを呼び出すだけです:
irb> nina.save
=> true
15 SQLによる検索
テーブル内のレコードを検索するために独自のSQLを使用したい場合は、find_by_sqlを使用できます。find_by_sqlメソッドは、基になるクエリが単一のレコードを返す場合でも、オブジェクトの配列を返します。たとえば、次のクエリを実行できます:
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sqlは、データベースへのカスタムなクエリを実行し、インスタンス化されたオブジェクトを取得する簡単な方法を提供します。
15.1 select_all
find_by_sqlには、connection.select_allという類似のメソッドがあります。select_allは、find_by_sqlと同様にカスタムなSQLを使用してデータベースからオブジェクトを取得しますが、オブジェクトをインスタンス化しません。このメソッドはActiveRecord::Resultクラスのインスタンスを返し、このオブジェクトにto_aを呼び出すと、レコードを示すハッシュの配列が返されます。
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
15.2 pluck
pluckは、現在の関連から指定された名前の列の値を取得するために使用できます。引数として列名のリストを受け取り、指定された列の値の配列を対応するデータ型で返します。
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluckを使用すると、次のようなコードを置き換えることができます。
Customer.select(:id).map { |c| c.id }
# または
Customer.select(:id).map(&:id)
# または
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
次のようになります。
Customer.pluck(:id)
# または
Customer.pluck(:id, :first_name)
pluckは、selectとは異なり、データベースの結果を直接RubyのArrayに変換します。これにより、大きなクエリや頻繁に実行されるクエリのパフォーマンスが向上する場合があります。ただし、モデルのメソッドのオーバーライドは利用できません。たとえば:
class Customer < ApplicationRecord
def name
"I am #{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["I am David", "I am Jeremy", "I am Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
単一のテーブルからフィールドをクエリするだけでなく、複数のテーブルからもクエリすることができます。
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
さらに、selectや他のRelationスコープとは異なり、pluckは即時クエリをトリガーし、そのため他のスコープと連鎖することはできませんが、既に構築されたスコープとは動作します。
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
注意:pluckを使用すると、関連オブジェクトにinclude値が含まれている場合、必要なくてもイーガーローディングがトリガーされます。たとえば:
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
これを回避する方法の1つは、includesをunscopeすることです。
irb> assoc.unscope(:includes).pluck(:id)
15.3 pick
pickは、現在の関連から指定された名前の列の値を取得するために使用できます。引数として列名のリストを受け取り、指定された列の値の配列を対応するデータ型で返します。pickは、すでに1行に制限された関連がある場合に主に有用なrelation.limit(1).pluck(*column_names).firstの省略形です。
pickを使用すると、次のようなコードを置き換えることができます。
Customer.where(id: 1).pluck(:id).first
次のようになります。
Customer.where(id: 1).pick(:id)
15.4 ids
idsは、テーブルの主キーを使用して関連のすべてのIDを取得するために使用できます。
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
16 オブジェクトの存在
オブジェクトの存在を確認するだけであれば、exists?というメソッドがあります。このメソッドは、findと同じクエリを使用してデータベースをクエリしますが、オブジェクトまたはオブジェクトのコレクションではなく、trueまたはfalseを返します。
Customer.exists?(1)
exists?メソッドは複数の値も受け取ることができますが、その場合、いずれかのレコードが存在する場合にtrueを返します。
Customer.exists?(id: [1, 2, 3])
# または
Customer.exists?(first_name: ['Jane', 'Sergei'])
モデルまたは関連に対して引数なしでexists?を使用することもできます。
Customer.where(first_name: 'Ryan').exists?
上記の場合、first_nameが'Ryan'の顧客が少なくとも1人いる場合はtrueを返し、それ以外の場合はfalseを返します。
Customer.exists?
上記の場合、customersテーブルが空であればfalseを返し、それ以外の場合はtrueを返します。
モデルまたは関連に対して存在を確認するためにany?とmany?も使用できます。many?はSQLのcountを使用してアイテムの存在を判断します。
```ruby
モデルを介して
Order.any?
SELECT 1 FROM orders LIMIT 1
Order.many?
SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
名前付きスコープを介して
Order.shipped.any?
SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
関連を介して
Book.where(out_of_print: true).any? Book.where(out_of_print: true).many?
関連を介して
Customer.first.orders.any? Customer.first.orders.many? ```
17 計算
このセクションでは、この前書きでcountを例として使用していますが、説明されているオプションはすべてのサブセクションに適用されます。
すべての計算メソッドは、モデル自体に直接適用することもできます。
irb> Customer.count
SELECT COUNT(*) FROM customers
またはリレーションに適用することもできます。
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
複雑な計算を実行するために、リレーションに対してさまざまな検索メソッドを使用することもできます。
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
これにより、次のクエリが実行されます。
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
ここで、Orderはenum status: [ :shipped, :being_packed, :cancelled ]を持っていると仮定しています。
17.1 count
モデルのテーブル内のレコード数を確認するには、Customer.countと呼び出すことができます。これにより、数が返されます。
より具体的に、データベースにタイトルが存在するすべての顧客を見つけたい場合は、Customer.count(:title)を使用できます。
オプションについては、親セクション計算を参照してください。
17.2 average
テーブル内の特定の数値の平均値を表示したい場合は、テーブルに関連するクラスに対してaverageメソッドを呼び出すことができます。このメソッド呼び出しは次のようになります。
Order.average("subtotal")
これにより、フィールドの平均値を表す数値(3.14159265などの浮動小数点数)が返されます。
オプションについては、親セクション計算を参照してください。
17.3 minimum
テーブル内のフィールドの最小値を見つけたい場合は、テーブルに関連するクラスに対してminimumメソッドを呼び出すことができます。このメソッド呼び出しは次のようになります。
Order.minimum("subtotal")
オプションについては、親セクション計算を参照してください。
17.4 maximum
テーブル内のフィールドの最大値を見つけたい場合は、テーブルに関連するクラスに対してmaximumメソッドを呼び出すことができます。このメソッド呼び出しは次のようになります。
Order.maximum("subtotal")
オプションについては、親セクション計算を参照してください。
17.5 sum
テーブル内のすべてのレコードのフィールドの合計値を見つけたい場合は、テーブルに関連するクラスに対してsumメソッドを呼び出すことができます。このメソッド呼び出しは次のようになります。
Order.sum("subtotal")
オプションについては、親セクション計算を参照してください。
18 EXPLAINの実行
リレーションに対してexplainを実行することができます。EXPLAINの出力はデータベースごとに異なります。
たとえば、次のコードを実行すると、
Customer.where(id: 1).joins(:orders).explain
次のような結果が得られるかもしれません。
EXPLAIN SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
MySQLとMariaDBでは、このような結果が得られます。
Active Recordは、対応するデータベースシェルと同様のプリティプリントを実行します。したがって、PostgreSQLアダプタを使用して同じクエリを実行すると、
EXPLAIN SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
となります。
イーガーローディングは、裏で複数のクエリをトリガーする場合があり、一部のクエリは前のクエリの結果を必要とする場合があります。そのため、explainは実際にクエリを実行し、その後クエリプランを要求します。たとえば、
ruby
Customer.where(id: 1).includes(:orders).explain
MySQLとMariaDBの場合、次のような結果が得られる場合があります。
EXPLAIN SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
PostgreSQLの場合、次のような結果が得られる場合があります。
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
18.1 Explainオプション
PostgreSQLとMySQLをサポートしているデータベースとアダプタの場合、より詳細な分析を提供するためにオプションを渡すことができます。
PostgreSQLを使用する場合、次のようなコード:
Customer.where(id: 1).joins(:orders).explain(:analyze, :verbose)
次の結果が得られます:
EXPLAIN (ANALYZE, VERBOSE) SELECT "shop_accounts".* FROM "shop_accounts" INNER JOIN "customers" ON "customers"."id" = "shop_accounts"."customer_id" WHERE "shop_accounts"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.30..16.37 rows=1 width=24) (actual time=0.003..0.004 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Inner Unique: true
-> Index Scan using shop_accounts_pkey on public.shop_accounts (cost=0.15..8.17 rows=1 width=24) (actual time=0.003..0.003 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Index Cond: (shop_accounts.id = '1'::bigint)
-> Index Only Scan using customers_pkey on public.customers (cost=0.15..8.17 rows=1 width=8) (never executed)
Output: customers.id
Index Cond: (customers.id = shop_accounts.customer_id)
Heap Fetches: 0
Planning Time: 0.063 ms
Execution Time: 0.011 ms
(12 rows)
MySQLまたはMariaDBを使用する場合、次のようなコード:
Customer.where(id: 1).joins(:orders).explain(:analyze)
次の結果が得られます:
ANALYZE SELECT `shop_accounts`.* FROM `shop_accounts` INNER JOIN `customers` ON `customers`.`id` = `shop_accounts`.`customer_id` WHERE `shop_accounts`.`id` = 1
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | r_rows | filtered | r_filtered | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | no matching row in const table |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
1 row in set (0.00 sec)
注意: EXPLAINおよびANALYZEオプションは、MySQLとMariaDBのバージョンによって異なる場合があります。 (MySQL 5.7, MySQL 8.0, MariaDB)
18.2 EXPLAINの解釈
EXPLAINの出力の解釈は、このガイドの範囲外です。 次のポイントが役立つかもしれません:
SQLite3: EXPLAIN QUERY PLAN
MySQL: EXPLAIN Output Format
MariaDB: EXPLAIN
PostgreSQL: Using EXPLAIN
フィードバック
このガイドの品質向上にご協力ください。
タイポや事実の誤りを見つけた場合は、ぜひ貢献してください。 開始するには、ドキュメントへの貢献セクションを読んでください。
不完全なコンテンツや最新でない情報も見つかるかもしれません。 メインのドキュメントに不足しているドキュメントを追加してください。 修正済みかどうかは、まずEdge Guidesを確認してください。 スタイルと規約については、Ruby on Rails Guides Guidelinesを確認してください。
修正すべき点を見つけたが、自分で修正できない場合は、 問題を報告してください。
そして最後に、Ruby on Railsのドキュメントに関するあらゆる議論は、公式のRuby on Railsフォーラムで大歓迎です。