1 Active Record 쿼리 인터페이스란 무엇인가?
데이터베이스 레코드를 찾기 위해 원시 SQL을 사용하는 것에 익숙하다면, 일반적으로 Rails에서 동일한 작업을 수행하는 더 좋은 방법이 있다는 것을 알게 될 것입니다. Active Record는 대부분의 경우 SQL을 사용할 필요 없이 작업을 수행할 수 있도록 해줍니다.
Active Record는 데이터베이스에서 쿼리를 수행하며, MySQL, MariaDB, PostgreSQL 및 SQLite를 포함한 대부분의 데이터베이스 시스템과 호환됩니다. 사용 중인 데이터베이스 시스템에 관계없이 Active Record 메소드 형식은 항상 동일합니다.
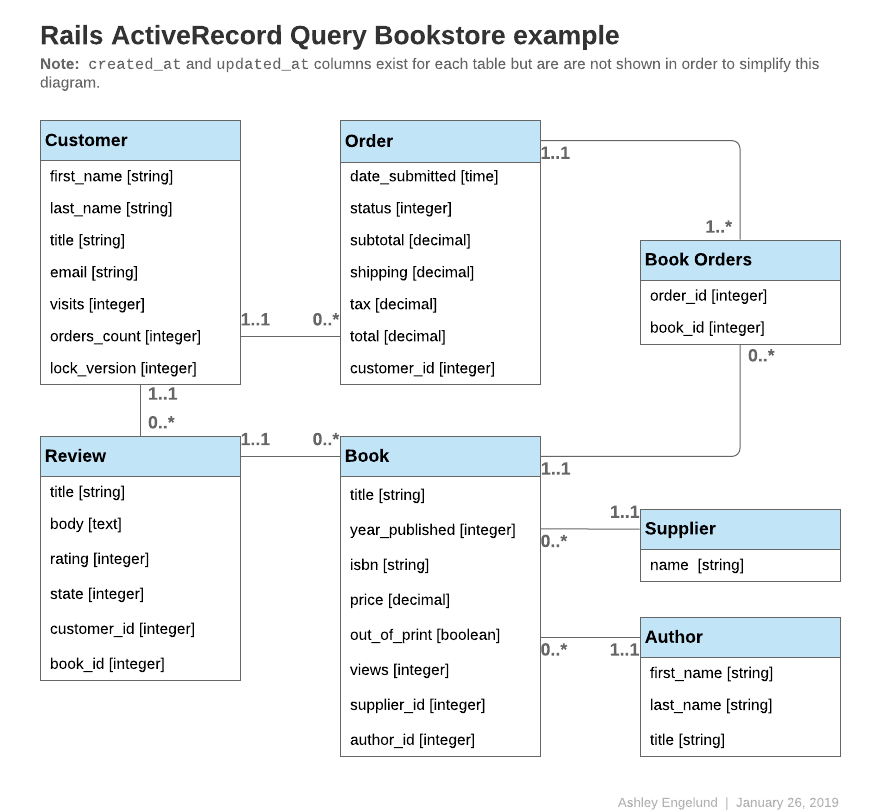
이 가이드의 코드 예제는 다음 중 하나 이상의 모델을 참조합니다.
팁: 다음 모델은 id를 기본 키로 사용합니다(다른 값으로 지정되지 않은 경우).
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where(created_at: ...time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
2 데이터베이스에서 객체 검색하기
데이터베이스에서 객체를 검색하기 위해 Active Record는 여러 개의 검색 메소드를 제공합니다. 각 검색 메소드는 원시 SQL을 작성하지 않고도 데이터베이스에서 특정 쿼리를 수행할 수 있도록 인수를 전달할 수 있습니다.
다음은 사용 가능한 메소드입니다.
annotatefindcreate_withdistincteager_loadextendingextract_associatedfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetoptimizer_hintsorderpreloadreadonlyreferencesreorderreselectregroupreverse_orderselectwhere
where 및 group과 같이 컬렉션을 반환하는 검색 메소드는 ActiveRecord::Relation의 인스턴스를 반환합니다. find 및 first와 같이 단일 엔티티를 찾는 메소드는 모델의 단일 인스턴스를 반환합니다.
Model.find(options)의 주요 작업은 다음과 같이 요약할 수 있습니다.
- 제공된 옵션을 동등한 SQL 쿼리로 변환합니다.
- SQL 쿼리를 실행하고 데이터베이스에서 해당 결과를 검색합니다.
- 결과 행마다 적절한 모델의 동등한 루비 객체를 인스턴스화합니다.
after_find및after_initialize콜백을 실행합니다(있는 경우).
2.1 단일 객체 검색
Active Record는 단일 객체를 검색하는 여러 가지 방법을 제공합니다.
2.1.1 find
find 메소드를 사용하여 지정된 기본 키에 해당하는 객체를 검색할 수 있습니다. 예를 들어:
# 기본 키 (id)가 10인 고객을 찾습니다.
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
위의 SQL과 동일한 쿼리는 다음과 같습니다.
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
find 메소드는 일치하는 레코드가 없는 경우 ActiveRecord::RecordNotFound 예외를 발생시킵니다.
이 메소드를 사용하여 여러 객체를 쿼리할 수도 있습니다. find 메소드를 호출하고 기본 키의 배열을 전달하면, 반환되는 값은 공급된 기본 키에 대한 모든 일치하는 레코드를 포함하는 배열입니다. 예를 들어:
```irb
주요 키가 1과 10인 고객을 찾습니다.
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers WHERE (customers.id IN (1,10))
경고: find 메소드는 제공된 주요 키에 대해 일치하는 레코드가 모두 찾아지지 않으면 ActiveRecord::RecordNotFound 예외를 발생시킵니다.
2.1.2 take
take 메소드는 암시적인 정렬 없이 레코드를 가져옵니다. 예를 들어:
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers LIMIT 1
take 메소드는 레코드를 찾지 못하면 nil을 반환하며 예외는 발생하지 않습니다.
take 메소드에 숫자 인수를 전달하여 해당 수의 결과를 반환할 수 있습니다. 예를 들어:
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers LIMIT 2
take! 메소드는 take와 동일하게 작동하지만 일치하는 레코드가 없으면 ActiveRecord::RecordNotFound를 발생시킵니다.
팁: 검색된 레코드는 데이터베이스 엔진에 따라 다를 수 있습니다.
2.1.3 first
first 메소드는 주요 키(기본값)로 정렬된 첫 번째 레코드를 찾습니다. 예를 들어:
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
first 메소드는 일치하는 레코드를 찾지 못하면 nil을 반환하며 예외는 발생하지 않습니다.
기본 범위에 정렬 메소드가 포함되어 있는 경우 first는 이 정렬에 따라 첫 번째 레코드를 반환합니다.
first 메소드에 숫자 인수를 전달하여 해당 수의 결과를 반환할 수 있습니다. 예를 들어:
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
order를 사용하여 정렬된 컬렉션에서 first는 order에 지정된 속성에 따라 첫 번째 레코드를 반환합니다.
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
first! 메소드는 first와 동일하게 작동하지만 일치하는 레코드가 없으면 ActiveRecord::RecordNotFound를 발생시킵니다.
2.1.4 last
last 메소드는 주요 키(기본값)로 정렬된 마지막 레코드를 찾습니다. 예를 들어:
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
last 메소드는 일치하는 레코드를 찾지 못하면 nil을 반환하며 예외는 발생하지 않습니다.
기본 범위에 정렬 메소드가 포함되어 있는 경우 last는 이 정렬에 따라 마지막 레코드를 반환합니다.
last 메소드에 숫자 인수를 전달하여 해당 수의 결과를 반환할 수 있습니다. 예를 들어:
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
order를 사용하여 정렬된 컬렉션에서 last는 order에 지정된 속성에 따라 마지막 레코드를 반환합니다.
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
last! 메소드는 last와 동일하게 작동하지만 일치하는 레코드가 없으면 ActiveRecord::RecordNotFound를 발생시킵니다.
2.1.5 find_by
find_by 메소드는 일치하는 조건을 가진 첫 번째 레코드를 찾습니다. 예를 들어:
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
다음과 같이 작성하는 것과 동일합니다:
Customer.where(first_name: 'Lifo').take
위의 SQL과 동일한 쿼리는 다음과 같습니다:
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
위의 SQL에서는 ORDER BY가 없음을 유의하십시오. find_by 조건이 여러 레코드와 일치할 수 있는 경우, 결정론적인 결과를 보장하기 위해 정렬을 적용해야 합니다.
find_by! 메서드는 find_by와 정확히 동일하게 동작하지만, 일치하는 레코드가 없는 경우 ActiveRecord::RecordNotFound를 발생시킵니다. 예를 들어:
irb> Customer.find_by! first_name: 'does not exist'
ActiveRecord::RecordNotFound
이는 다음과 같이 작성하는 것과 동일합니다:
Customer.where(first_name: 'does not exist').take!
2.2 일괄적으로 여러 객체 검색하기
우리는 종종 대량의 레코드를 반복해서 처리해야 할 때가 있습니다. 예를 들어 대량의 고객에게 뉴스레터를 보내거나 데이터를 내보낼 때입니다.
이는 간단해 보일 수 있습니다:
# 테이블이 큰 경우 메모리를 너무 많이 소비할 수 있습니다.
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
하지만 이 접근 방식은 테이블 크기가 커질수록 점점 비실용적이 됩니다. 왜냐하면 Customer.all.each는 Active Record에게 한 번에 전체 테이블을 가져오도록 지시하고, 각 행마다 모델 객체를 빌드한 다음 모델 객체의 전체 배열을 메모리에 유지하기 때문입니다. 실제로 레코드 수가 많으면 전체 컬렉션이 사용 가능한 메모리 양을 초과할 수 있습니다.
Rails는 이 문제를 해결하기 위해 기록을 메모리에 친화적인 일괄 처리를 위해 레코드를 나누는 두 가지 메서드를 제공합니다. 첫 번째 메서드인 find_each는 레코드를 검색하고 각 레코드를 모델로서 블록에 개별적으로 전달합니다. 두 번째 메서드인 find_in_batches는 레코드를 검색하고 전체 일괄을 모델의 배열로서 블록에 전달합니다.
팁: find_each 및 find_in_batches 메서드는 한 번에 모든 레코드를 메모리에 저장할 수 없는 대량의 레코드를 일괄 처리하는 데 사용됩니다. 1000개의 레코드를 루프하는 것만 필요한 경우 일반적인 검색 메서드가 선호됩니다.
2.2.1 find_each
find_each 메서드는 레코드를 일괄적으로 검색하고 각 레코드를 블록에 개별적으로 전달합니다. 다음 예제에서 find_each는 1000개씩 고객을 일괄적으로 검색하고 하나씩 블록에 전달합니다:
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
이 과정은 필요에 따라 더 많은 일괄을 가져와서 모든 레코드가 처리될 때까지 반복됩니다.
find_each는 위에서 본 것처럼 모델 클래스에서 작동하며, 관계에서도 작동합니다:
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
단, 정렬이 없는 경우에만 작동합니다. 이는 메서드가 반복하기 위해 내부적으로 순서를 강제해야 하기 때문입니다.
수신자에 정렬이 있는 경우 동작은 config.active_record.error_on_ignored_order 플래그에 따라 달라집니다. true인 경우 ArgumentError가 발생하고, 그렇지 않으면 순서가 무시되고 경고가 발생합니다(기본값). 이는 아래에서 설명하는 :error_on_ignore 옵션으로 재정의할 수 있습니다.
2.2.1.1 find_each의 옵션
:batch_size
:batch_size 옵션을 사용하면 각 일괄에서 검색할 레코드 수를 지정할 수 있습니다. 예를 들어 5000개씩 일괄로 레코드를 검색하려면:
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
기본적으로 레코드는 기본 키의 오름차순으로 가져옵니다. :start 옵션을 사용하면 가장 낮은 ID가 필요한 것이 아닌 경우에 시퀀스의 첫 번째 ID를 구성할 수 있습니다. 예를 들어, 2000부터 시작하는 기본 키를 가진 고객에게만 뉴스레터를 보내려는 경우:
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
start 옵션과 유사하게, :finish를 사용하면 가장 높은 ID가 필요한 것이 아닌 경우에 시퀀스의 마지막 ID를 구성할 수 있습니다. 예를 들어, 2000부터 10000까지의 기본 키를 가진 고객에게만 뉴스레터를 보내려는 경우:
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
다른 예로는 동일한 처리 큐를 처리하는 여러 워커를 원하는 경우입니다. 각 워커가 10000개의 레코드를 처리하도록 하려면 각 워커에 적절한 :start 및 :finish 옵션을 설정하면 됩니다.
:error_on_ignore
관계에 정렬이 있는 경우에 순서가 무시될 때 오류가 발생해야 하는지를 지정하기 위해 응용 프로그램 구성을 재정의합니다.
:order
기본 키 순서를 지정합니다(:asc 또는 :desc일 수 있음). 기본값은 :asc입니다.
ruby
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
2.2.2 find_in_batches
find_in_batches 메소드는 find_each와 유사하게 레코드의 일꾼을 검색합니다. 차이점은 find_in_batches는 개별적으로가 아닌 모델의 배열로 블록에 일꾼을 제공합니다. 다음 예제는 최대 1000명의 고객을 한 번에 배열로 제공하고, 마지막 블록에는 남은 고객을 포함합니다:
# 1000명의 고객을 한 번에 배열로 add_customers에 전달합니다.
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batches는 위에서 본 것처럼 모델 클래스뿐만 아니라 관계에도 작동합니다:
# 최근 활동한 1000명의 고객을 한 번에 배열로 add_customers에 전달합니다.
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
내부적으로 반복을 위해 순서를 강제해야하기 때문에 정렬이 없는 경우에만 작동합니다.
2.2.2.1 find_in_batches의 옵션
find_in_batches 메소드는 find_each와 동일한 옵션을 받습니다:
:batch_size
find_each와 마찬가지로 batch_size는 각 그룹에서 검색할 레코드의 수를 설정합니다. 예를 들어, 2500개의 레코드를 한 번에 검색하려면 다음과 같이 지정할 수 있습니다:
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
start 옵션은 레코드를 선택할 시작 ID를 지정할 수 있습니다. 기본적으로 레코드는 기본 키의 오름차순으로 검색됩니다. 예를 들어, 2500개의 레코드로 시작하는 ID 5000의 고객을 검색하려면 다음 코드를 사용할 수 있습니다:
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
finish 옵션은 검색할 레코드의 끝 ID를 지정할 수 있습니다. 아래 코드는 ID 7000까지 고객을 검색하는 경우를 보여줍니다:
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
error_on_ignore 옵션은 관계에 특정 순서가 있는 경우 오류를 발생시킬지 여부를 지정합니다.
3 조건
where 메소드는 반환되는 레코드를 제한하는 조건을 지정할 수 있습니다. 이는 SQL 문의 WHERE 부분을 나타냅니다. 조건은 문자열, 배열 또는 해시로 지정할 수 있습니다.
3.1 순수 문자열 조건
조건을 추가하려면 Book.where("title = 'Introduction to Algorithms'")와 같이 지정할 수 있습니다. 이는 title 필드 값이 'Introduction to Algorithms'인 모든 책을 찾습니다.
경고: 순수 문자열로 조건을 직접 작성하면 SQL 인젝션 취약점에 노출될 수 있습니다. 예를 들어, Book.where("title LIKE '%#{params[:title]}%'")은 안전하지 않습니다. 조건을 처리하는 우선적인 방법은 배열을 사용하는 것입니다.
3.2 배열 조건
제목이 매개변수에서 가져올 수 있는 경우 어떻게 될까요? 그렇다면 다음과 같이 찾을 수 있습니다:
Book.where("title = ?", params[:title])
Active Record는 첫 번째 인수를 조건 문자열로 사용하고 추가 인수는 그 안의 물음표 (?)를 대체합니다.
여러 조건을 지정하려면:
Book.where("title = ? AND out_of_print = ?", params[:title], false)
이 예제에서 첫 번째 물음표는 params[:title]의 값으로 대체되고 두 번째 물음표는 어댑터에 따라 false의 SQL 표현으로 대체됩니다.
이 코드는 다음 코드보다 훨씬 좋습니다:
Book.where("title = ?", params[:title])
이 코드는 다음 코드보다 훨씬 좋습니다:
Book.where("title = #{params[:title]}")
인수의 안전성 때문입니다. 변수를 직접 조건 문자열에 넣으면 변수가 데이터베이스로 그대로 전달됩니다. 이는 악의적인 의도를 가진 사용자로부터 직접적으로 이스케이프되지 않은 변수가 될 것입니다. 이렇게 하면 사용자가 데이터베이스를 악용할 수 있으므로 데이터베이스 전체가 위험에 빠집니다. 인수를 직접 조건 문자열 안에 넣지 마세요.
팁: SQL 인젝션의 위험에 대한 자세한 내용은 Ruby on Rails 보안 가이드를 참조하세요.
3.2.1 플레이스홀더 조건
매개변수의 (?) 대체 스타일과 마찬가지로 조건 문자열에 키와 해당 키/값 해시를 함께 지정할 수도 있습니다:
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
이렇게 하면 변수 조건이 많을 때 더 명확하게 읽을 수 있습니다.
3.2.2 LIKE를 사용하는 조건
조건 인수는 SQL 인젝션을 방지하기 위해 자동으로 이스케이프되지만 SQL LIKE 와일드카드(% 및 _)는 **이스케이프되지 않습니다. 이는 인자로서 이스케이프되지 않은 값을 사용하면 예상치 못한 동작을 일으킬 수 있습니다. 예를 들어:
ruby
Book.order(:created_at).order(:title)
This will generate SQL like this:
SELECT * FROM books ORDER BY created_at ASC, title ASC
You can also use the reorder method to replace any existing order with a new one:
Book.order(:created_at).reorder(:title)
This will generate SQL like this:
SELECT * FROM books ORDER BY title ASC
3.3 Random Ordering
To retrieve records in a random order, you can use the order method with the RANDOM() function:
Book.order("RANDOM()")
This will generate SQL like this:
SELECT * FROM books ORDER BY RANDOM()
3.4 Reverse Ordering
To retrieve records in reverse order, you can use the reverse_order method:
Book.order(:created_at).reverse_order
This will generate SQL like this:
SELECT * FROM books ORDER BY created_at DESC
3.5 Custom Ordering
If you need to order records using a custom SQL expression, you can use the order method with a string argument:
Book.order("CASE WHEN out_of_print = 1 THEN 0 ELSE 1 END")
This will generate SQL like this:
SELECT * FROM books ORDER BY CASE WHEN out_of_print = 1 THEN 0 ELSE 1 END
3.6 Nulls Ordering
By default, NULL values are ordered last in ascending order and first in descending order. If you want to change this behavior, you can use the nulls_first or nulls_last methods:
Book.order(:title).nulls_first
This will generate SQL like this:
SELECT * FROM books ORDER BY title ASC NULLS FIRST
Book.order(:title).nulls_last
This will generate SQL like this:
SELECT * FROM books ORDER BY title ASC NULLS LAST
3.7 Reversing Order
To reverse the order of a relation, you can use the reverse method:
Book.order(:created_at).reverse
This will generate SQL like this:
SELECT * FROM books ORDER BY created_at DESC
3.8 Randomizing Order
To randomize the order of a relation, you can use the shuffle method:
Book.order(:created_at).shuffle
This will generate SQL like this:
SELECT * FROM books ORDER BY RANDOM()
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
경고: 대부분의 데이터베이스 시스템에서 select, pluck, ids와 같은 메소드를 사용하여 결과 집합에서 distinct로 필드를 선택하는 경우, order 메소드는 order 절에 사용된 필드가 select 목록에 포함되지 않으면 ActiveRecord::StatementInvalid 예외를 발생시킵니다. 결과 집합에서 필드를 선택하는 방법에 대해서는 다음 섹션을 참조하십시오.
4 특정 필드 선택하기
기본적으로 Model.find는 select *를 사용하여 결과 집합에서 모든 필드를 선택합니다.
결과 집합에서 일부 필드만 선택하려면 select 메소드를 사용하여 해당 부분집합을 지정할 수 있습니다.
예를 들어, isbn과 out_of_print 열만 선택하려면 다음과 같이 지정할 수 있습니다:
Book.select(:isbn, :out_of_print)
# 또는
Book.select("isbn, out_of_print")
이 find 호출에 사용되는 SQL 쿼리는 다음과 같습니다:
SELECT isbn, out_of_print FROM books
주의해야 할 점은 이렇게하면 선택한 필드만으로 모델 객체를 초기화하게 된다는 것입니다. 초기화된 레코드에 없는 필드에 액세스하려고하면 다음과 같은 오류가 발생합니다:
ActiveModel::MissingAttributeError: missing attribute '<attribute>' for Book
여기서 <attribute>는 요청한 속성입니다. id 메소드는 ActiveRecord::MissingAttributeError를 발생시키지 않으므로 연관 관계와 함께 작업할 때 주의하십시오. 연관 관계는 id 메소드가 제대로 작동해야합니다.
특정 필드에서 고유한 값 당 하나의 레코드 만 가져 오려면 distinct를 사용할 수 있습니다:
Customer.select(:last_name).distinct
이는 다음과 같은 SQL을 생성합니다:
SELECT DISTINCT last_name FROM customers
고유성 제약 조건을 제거 할 수도 있습니다:
# 고유한 last_names을 반환합니다
query = Customer.select(:last_name).distinct
# 중복이있는 경우 모든 last_names을 반환합니다
query.distinct(false)
5 제한 및 오프셋
Model.find에서 발생하는 SQL에 LIMIT를 적용하려면 관계에있는 limit 및 offset 메소드를 사용하여 LIMIT를 지정할 수 있습니다.
limit을 사용하여 검색 할 레코드 수를 지정하고 offset을 사용하여 레코드를 반환하기 전에 건너 뛸 레코드 수를 지정할 수 있습니다. 예를 들어
Customer.limit(5)
는 최대 5 개의 고객을 반환하며 오프셋을 지정하지 않으므로 테이블의 첫 5 개를 반환합니다. 실행되는 SQL은 다음과 같습니다:
SELECT * FROM customers LIMIT 5
그에 offset을 추가하면
Customer.limit(5).offset(30)
대신 31 번째부터 시작하는 최대 5 개의 고객을 반환합니다. SQL은 다음과 같습니다:
SELECT * FROM customers LIMIT 5 OFFSET 30
6 그룹화
파인더에 의해 발생하는 SQL에 GROUP BY 절을 적용하려면 group 메소드를 사용할 수 있습니다.
예를 들어, 주문이 생성 된 날짜의 컬렉션을 찾으려면:
Order.select("created_at").group("created_at")
이렇게하면 데이터베이스에 주문이있는 각 날짜에 대해 단일 Order 객체가 생성됩니다.
실행되는 SQL은 다음과 같습니다:
SELECT created_at
FROM orders
GROUP BY created_at
6.1 그룹화 된 항목의 총계
단일 쿼리에서 그룹화 된 항목의 총계를 얻으려면 group 후에 count를 호출하십시오.
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
실행되는 SQL은 다음과 같습니다:
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
6.2 HAVING 조건
SQL은 HAVING 절을 사용하여 GROUP BY 필드에 대한 조건을 지정합니다. Model.find에 HAVING 절을 추가하려면 having 메소드를 find에 추가하면됩니다.
예를 들어:
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
실행되는 SQL은 다음과 같습니다:
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
이는 주문이 생성 된 날짜별로 그룹화되고 총액이 $200 이상인 주문 객체의 날짜와 총액을 반환합니다.
각 주문 객체의 total_price에는 다음과 같이 액세스 할 수 있습니다:
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# 첫 번째 Order 객체의 총 가격을 반환합니다
7 조건 재정의
7.1 unscope
unscope 메소드를 사용하여 특정 조건을 제거 할 수 있습니다. 예를 들어:
ruby
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
실행될 SQL:
SELECT * FROM books WHERE id > 100 LIMIT 20
-- `unscope` 없이 원래의 쿼리
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
where 절에서 특정 조건을 제거할 수도 있습니다. 예를 들어, 다음은 id 조건을 제거합니다:
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
unscope를 사용한 관계는 병합된 모든 관계에 영향을 미칩니다:
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
7.2 only
only 메소드를 사용하여 조건을 덮어쓸 수도 있습니다. 예를 들어:
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
실행될 SQL:
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- `only` 없이 원래의 쿼리
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
7.3 reselect
reselect 메소드는 기존의 select 문을 덮어씁니다. 예를 들어:
Book.select(:title, :isbn).reselect(:created_at)
실행될 SQL:
SELECT books.created_at FROM books
reselect 절을 사용하지 않은 경우와 비교해보면:
Book.select(:title, :isbn).select(:created_at)
실행될 SQL:
SELECT books.title, books.isbn, books.created_at FROM books
7.4 reorder
reorder 메소드는 기본 스코프의 순서를 덮어씁니다. 예를 들어, 클래스 정의에 다음이 포함되어 있는 경우:
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
다음을 실행하면:
Author.find(10).books
실행될 SQL:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
reorder 절을 사용하여 다른 방식으로 책을 정렬할 수 있습니다:
Author.find(10).books.reorder('year_published ASC')
실행될 SQL:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
7.5 reverse_order
reverse_order 메소드는 지정된 경우 정렬 절을 반대로 뒤집습니다.
Book.where("author_id > 10").order(:year_published).reverse_order
실행될 SQL:
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
쿼리에서 정렬 절이 지정되지 않은 경우, reverse_order는 기본 키를 역순으로 정렬합니다.
Book.where("author_id > 10").reverse_order
실행될 SQL:
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
reverse_order 메소드는 인자를 받지 않습니다.
7.6 rewhere
[rewhere][] 메소드는 기존의 이름이 지정된 where 조건을 덮어씁니다. 예를 들어:
Book.where(out_of_print: true).rewhere(out_of_print: false)
실행될 SQL:
SELECT * FROM books WHERE out_of_print = 0
rewhere 절을 사용하지 않은 경우, where 절은 AND로 결합됩니다:
Book.where(out_of_print: true).where(out_of_print: false)
실행될 SQL:
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
7.7 regroup
regroup 메소드는 기존의 이름이 지정된 group 조건을 덮어씁니다. 예를 들어:
Book.group(:author).regroup(:id)
실행될 SQL:
SELECT * FROM books GROUP BY id
regroup 절을 사용하지 않은 경우, group 절은 결합됩니다:
Book.group(:author).group(:id)
실행될 SQL:
SELECT * FROM books GROUP BY author, id
8 Null Relation
none 메소드는 레코드가 없는 연결 가능한 관계를 반환합니다. 반환된 관계에 연결된 후속 조건은 계속해서 빈 관계를 생성합니다. 이는 결과가 없을 수 있는 메소드나 스코프에 대한 연결 가능한 응답이 필요한 시나리오에서 유용합니다.
Book.none # 빈 Relation을 반환하고 쿼리를 실행하지 않습니다.
# 아래의 highlighted_reviews 메소드는 항상 Relation을 반환하는 것으로 예상됩니다.
Book.first.highlighted_reviews.average(:rating)
# => 책의 평균 평점을 반환합니다.
class Book
# 리뷰가 5개 이상인 경우 리뷰를 반환하고,
# 그렇지 않으면 아직 최소 기준을 충족하지 않는 리뷰 없음을 의미합니다.
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # 아직 최소 기준을 충족하지 않음
end
end
end
9 Readonly Objects
Active Record는 readonly 메소드를 제공하여 반환된 객체의 수정을 명시적으로 허용하지 않습니다. 읽기 전용 레코드를 수정하려는 시도는 성공하지 않으며, ActiveRecord::ReadOnlyRecord 예외가 발생합니다.
ruby
customer = Customer.readonly.first
customer.visits += 1
customer.save
customer가 명시적으로 읽기 전용 객체로 설정되어 있기 때문에, 위의 코드는 customer.save를 호출할 때 visits의 업데이트된 값과 함께 ActiveRecord::ReadOnlyRecord 예외를 발생시킵니다.
10 레코드 업데이트를 위한 락 걸기
락은 데이터베이스에서 레코드를 업데이트할 때 경합 조건을 방지하고 원자적인 업데이트를 보장하는 데 도움이 됩니다.
Active Record는 두 가지 락 메커니즘을 제공합니다.
- 낙관적 락
- 비관적 락
10.1 낙관적 락
낙관적 락은 여러 사용자가 동일한 레코드에 대한 편집을 할 수 있도록 허용하며, 데이터와 충돌이 최소화되었다고 가정합니다. 이를 위해 낙관적 락은 레코드를 열었을 때 다른 프로세스가 해당 레코드를 변경했는지 확인합니다. 그렇게 된 경우 ActiveRecord::StaleObjectError 예외가 발생하고 업데이트는 무시됩니다.
낙관적 락 컬럼
낙관적 락을 사용하려면 테이블에 lock_version이라는 integer 타입의 컬럼이 있어야 합니다. 레코드가 업데이트될 때마다 Active Record는 lock_version 컬럼을 증가시킵니다. 만약 업데이트 요청이 lock_version 필드에 현재 데이터베이스의 lock_version 컬럼보다 낮은 값을 가지고 있으면, 업데이트 요청은 ActiveRecord::StaleObjectError와 함께 실패합니다.
예를 들어:
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # ActiveRecord::StaleObjectError 예외 발생
이러한 충돌을 처리하기 위해 예외를 잡고 롤백, 병합 또는 충돌을 해결하기 위해 필요한 비즈니스 로직을 적용하는 것은 사용자의 책임입니다.
이 동작은 ActiveRecord::Base.lock_optimistically = false로 설정하여 비활성화할 수 있습니다.
lock_version 컬럼의 이름을 재정의하려면 ActiveRecord::Base는 locking_column이라는 클래스 속성을 제공합니다:
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
10.2 비관적 락
비관적 락은 기반 데이터베이스에서 제공하는 락 메커니즘을 사용합니다. lock을 사용하여 관련된 행에 독점적인 락을 얻습니다. lock을 사용하는 관계는 일반적으로 데드락 상황을 방지하기 위해 트랜잭션 내에서 래핑됩니다.
예를 들어:
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, second edition'
book.save!
end
위의 세션은 MySQL 백엔드에 대해 다음과 같은 SQL을 생성합니다:
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, second edition' WHERE id = 1
SQL (0.8ms) COMMIT
lock 메서드에 대해 원시 SQL을 전달하여 다른 유형의 락을 허용할 수도 있습니다. 예를 들어, MySQL에는 레코드를 락하고 다른 쿼리에서 읽을 수 있도록하는 LOCK IN SHARE MODE라는 표현이 있습니다. 이 표현을 지정하려면 락 옵션으로 전달하면 됩니다:
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
참고: lock 메서드에 전달하는 원시 SQL을 지원하는 데이터베이스여야 합니다.
모델의 인스턴스가 이미 있는 경우 다음 코드를 사용하여 트랜잭션을 시작하고 락을 한 번에 얻을 수 있습니다:
book = Book.first
book.with_lock do
# 이 블록은 트랜잭션 내에서 호출됩니다.
# book은 이미 락이 걸려 있습니다.
book.increment!(:views)
end
11 테이블 조인하기
Active Record는 결과 SQL에 JOIN 절을 지정하기 위한 두 가지 검색 메서드를 제공합니다: joins와 left_outer_joins.
joins는 INNER JOIN 또는 사용자 정의 쿼리에 사용되며, left_outer_joins는 LEFT OUTER JOIN을 사용하는 쿼리에 사용됩니다.
11.1 joins
joins 메서드를 사용하는 여러 가지 방법이 있습니다.
11.1.1 문자열 SQL 조각 사용
joins에 JOIN 절을 지정하는 원시 SQL을 제공할 수 있습니다:
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
이렇게 하면 다음과 같은 SQL이 생성됩니다:
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
11.1.2 배열/해시 형태의 명명된 연관 관계 사용
Active Record는 joins 메서드를 사용할 때 모델에 정의된 연관 관계의 이름을 사용하여 해당 연관 관계에 대한 JOIN 절을 지정하는 단축키로 사용할 수 있습니다.
다음은 모두 INNER JOIN을 사용하여 예상된 조인 쿼리를 생성합니다:
11.1.2.1 단일 연관 관계 조인
Book.joins(:reviews)
이렇게 하면 다음과 같은 SQL이 생성됩니다:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
또는 영어로 표현하면 "리뷰가 있는 모든 책에 대한 Book 객체를 반환합니다". 책에 여러 개의 리뷰가 있는 경우 중복된 책이 표시됩니다. 고유한 책을 원하는 경우 Book.joins(:reviews).distinct를 사용할 수 있습니다.
11.1.3 여러 개의 연관 관계 조인하기
Book.joins(:author, :reviews)
이렇게 작성하면 다음과 같은 SQL을 생성합니다:
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
또는 영어로 표현하면 "최소한 하나의 리뷰가 있는 작가와 함께 있는 모든 책을 반환합니다". 여러 개의 리뷰가 있는 책은 여러 번 나타날 수 있음에 유의하세요.
11.1.3.1 중첩된 연관 관계 조인하기 (단일 레벨)
Book.joins(reviews: :customer)
이렇게 작성하면 다음과 같은 SQL을 생성합니다:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
또는 영어로 표현하면 "고객이 작성한 리뷰가 있는 모든 책을 반환합니다."
11.1.3.2 중첩된 연관 관계 조인하기 (다중 레벨)
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier])
이렇게 작성하면 다음과 같은 SQL을 생성합니다:
SELECT * FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
또는 영어로 표현하면 "리뷰가 있는 책을 가진 작가 중에서 고객이 주문한 책과 그 책의 공급업체를 반환합니다."
11.1.4 조인된 테이블에 조건 지정하기
일반적인 배열 조건과 문자열 조건을 사용하여 조인된 테이블에 조건을 지정할 수 있습니다. 해시 조건은 조인된 테이블에 조건을 지정하기 위한 특별한 구문을 제공합니다:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
이렇게 작성하면 created_at을 비교하기 위해 BETWEEN SQL 표현식을 사용하여 어제 생성된 주문이 있는 모든 고객을 찾습니다.
대체로 더 깔끔한 구문은 해시 조건을 중첩하는 것입니다:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
더 복잡한 조건이나 기존의 네임드 스코프를 재사용하기 위해서는 merge를 사용할 수 있습니다. 먼저, Order 모델에 새로운 네임드 스코프를 추가해 봅시다:
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
이제 merge를 사용하여 created_in_time_range 스코프를 병합할 수 있습니다:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
이렇게 작성하면 BETWEEN SQL 표현식을 사용하여 어제 생성된 주문이 있는 모든 고객을 찾습니다.
11.2 left_outer_joins
연관된 레코드가 있는지 여부에 상관없이 일련의 레코드를 선택하려면 left_outer_joins 메서드를 사용할 수 있습니다.
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
다음과 같은 SQL을 생성합니다:
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
즉 "모든 리뷰의 수와 함께 리뷰가 있는지 여부에 상관없이 모든 고객을 반환합니다."
11.3 where.associated와 where.missing
associated와 missing 쿼리 메서드를 사용하면 연관 관계의 존재 여부에 따라 일련의 레코드를 선택할 수 있습니다.
where.associated를 사용하는 방법:
Customer.where.associated(:reviews)
다음과 같은 SQL을 생성합니다:
SELECT customers.* FROM customers
INNER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NOT NULL
즉 "최소한 하나의 리뷰를 작성한 모든 고객을 반환합니다."
where.missing을 사용하는 방법:
Customer.where.missing(:reviews)
다음과 같은 SQL을 생성합니다:
SELECT customers.* FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NULL
즉 "리뷰를 작성하지 않은 모든 고객을 반환합니다".
12 Eager Loading Associations
Eager loading은 Model.find로 반환된 객체의 연관된 레코드를 가능한 한 적은 쿼리를 사용하여 로드하는 메커니즘입니다.
12.1 N + 1 Queries 문제
다음 코드를 고려해 보세요. 이 코드는 10개의 책을 찾고 그들의 작가의 성을 출력합니다:
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
이 코드는 처음에는 괜찮아 보입니다. 그러나 실행된 쿼리의 총 수에 문제가 있습니다. 위의 코드는 총 1번(10개의 책을 찾기 위해) + 10번(각 책마다 작가를 로드하기 위해) = 11번의 쿼리를 실행합니다.
12.1.1 N + 1 Queries 문제에 대한 해결책
Active Record를 사용하면 미리 로드될 모든 연관 관계를 지정할 수 있습니다.
사용할 수 있는 메서드는 다음과 같습니다:
12.2 includes
includes를 사용하면 Active Record는 지정된 모든 연관 관계를 가능한 한 적은 수의 쿼리를 사용하여 로드합니다.
includes 메서드를 사용하여 위의 예제를 다시 작성하면 작가를 eager load하기 위해 Book.limit(10)을 다음과 같이 변경할 수 있습니다:
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
위의 코드는 원래 경우의 11개의 쿼리와 달리 2개의 쿼리만 실행됩니다.
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
12.2.1 여러 개의 연관 관계를 Eager Loading하기
Active Record는 includes 메소드를 사용하여 배열, 해시 또는 중첩된 해시의 배열/해시를 사용하여 단일 Model.find 호출로 여러 개의 연관 관계를 eager loading 할 수 있습니다.
12.2.1.1 여러 개의 연관 관계 배열
Customer.includes(:orders, :reviews)
이는 모든 고객과 각각의 연관된 주문과 리뷰를 로드합니다.
12.2.1.2 중첩된 연관 관계 해시
Customer.includes(orders: { books: [:supplier, :author] }).find(1)
이는 id가 1인 고객을 찾고, 해당 고객에 대한 모든 연관된 주문, 모든 주문에 대한 책, 그리고 각 책의 저자와 공급업체를 eager loading합니다.
12.2.2 Eager Loaded 연관 관계에 조건 지정하기
Active Record는 joins와 마찬가지로 eager loaded 연관 관계에 조건을 지정할 수 있지만, 권장하는 방법은 joins를 사용하는 것입니다.
하지만 필요한 경우에는 일반적인 방법으로 where를 사용할 수 있습니다.
Author.includes(:books).where(books: { out_of_print: true })
이는 LEFT OUTER JOIN을 포함하는 쿼리를 생성하며, joins 메소드는 대신 INNER JOIN 함수를 사용하여 쿼리를 생성합니다.
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN books ON books.author_id = authors.id WHERE (books.out_of_print = 1)
where 조건이 없는 경우에는 일반적인 두 개의 쿼리 세트가 생성됩니다.
참고: 이와 같이 where를 사용하는 것은 해시를 전달할 때만 작동합니다. SQL 조각을 사용하는 경우에는 조인된 테이블을 강제로 지정하기 위해 references를 사용해야 합니다.
Author.includes(:books).where("books.out_of_print = true").references(:books)
이 includes 쿼리의 경우, 어떤 작가에 대해서도 책이 없는 경우에도 모든 작가가 여전히 로드됩니다. joins (INNER JOIN)을 사용하면 조인 조건이 일치해야 하므로 레코드가 반환되지 않습니다.
참고: 연관 관계가 조인의 일부로 eager loading되는 경우, 사용자 정의 select 절의 필드는 로드된 모델에 존재하지 않습니다. 이는 이러한 필드가 부모 레코드 또는 자식에 나타나야 하는지 모호하기 때문입니다.
12.3 preload
preload를 사용하면 Active Record는 각 지정된 연관 관계를 하나의 쿼리로 로드합니다.
N + 1 쿼리 문제를 다시 살펴보면, Book.limit(10)을 작성하여 저자를 미리 로드할 수 있습니다.
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
위의 코드는 원래 경우의 11개의 쿼리와 달리 2개의 쿼리만 실행됩니다.
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
참고: preload 메소드는 includes 메소드와 마찬가지로 배열, 해시 또는 중첩된 해시의 배열/해시를 사용하여 단일 Model.find 호출로 여러 개의 연관 관계를 로드하는 데 사용됩니다. 그러나 includes 메소드와 달리, preloaded 연관 관계에 대한 조건을 지정할 수 없습니다.
12.4 eager_load
eager_load를 사용하면 Active Record는 LEFT OUTER JOIN을 사용하여 모든 지정된 연관 관계를 로드합니다.
eager_load 메소드를 사용하여 N + 1이 발생한 경우의 경우, Book.limit(10)을 작성하여 저자를 로드할 수 있습니다.
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
위의 코드는 원래 경우의 11개의 쿼리와 달리 2개의 쿼리만 실행됩니다.
SELECT DISTINCT books.id FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id LIMIT 10
SELECT books.id AS t0_r0, books.last_name AS t0_r1, ...
FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id
WHERE books.id IN (1,2,3,4,5,6,7,8,9,10)
참고: eager_load 메소드는 includes 메소드와 마찬가지로 배열, 해시 또는 중첩된 해시의 배열/해시를 사용하여 단일 Model.find 호출로 여러 개의 연관 관계를 로드하는 데 사용됩니다. 또한 includes 메소드와 마찬가지로 eager loaded 연관 관계에 대한 조건을 지정할 수 있습니다.
12.5 strict_loading
Eager loading은 N + 1 쿼리를 방지할 수 있지만, 여전히 일부 연관 관계를 lazy loading할 수 있습니다. 모든 연관 관계가 lazy loading되지 않도록 하려면 strict_loading을 활성화할 수 있습니다.
관계에 strict loading 모드를 활성화하면 레코드가 연관 관계를 lazy loading하려고 시도하면 ActiveRecord::StrictLoadingViolationError가 발생합니다.
user = User.strict_loading.first
user.comments.to_a # ActiveRecord::StrictLoadingViolationError 발생
13 스코프
스코핑은 연관 객체나 모델에서 메소드 호출로 참조할 수 있는 일반적으로 사용되는 쿼리를 지정할 수 있게 해줍니다. 이러한 스코프를 사용하면 where, joins, includes와 같이 이전에 다룬 모든 메소드를 사용할 수 있습니다. 모든 스코프 본문은 ActiveRecord::Relation 또는 nil을 반환해야 하며, 이를 통해 추가 메소드(다른 스코프와 같은)를 호출할 수 있습니다.
간단한 스코프를 정의하기 위해 클래스 내부에서 scope 메소드를 사용하여 호출될 때 실행할 쿼리를 전달합니다:
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
out_of_print 스코프를 호출하기 위해 클래스나 Book 객체로 구성된 연관 객체 어디에서나 호출할 수 있습니다:
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # 모든 절판된 책
또는 Book 객체로 구성된 연관 객체에서 호출할 수 있습니다:
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # `author`의 모든 절판된 책
스코프는 스코프 내에서도 연쇄적으로 사용할 수 있습니다:
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
13.1 인수 전달
스코프에 인수를 전달할 수 있습니다:
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
클래스 메소드처럼 스코프를 호출할 수 있습니다:
irb> Book.costs_more_than(100.10)
그러나 이는 클래스 메소드에서 제공되는 기능을 중복해서 제공하는 것입니다.
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
이 메소드들은 여전히 연관 객체에서 접근할 수 있습니다:
irb> author.books.costs_more_than(100.10)
13.2 조건문 사용
스코프는 조건문을 활용할 수 있습니다:
class Order < ApplicationRecord
scope :created_before, ->(time) { where(created_at: ...time) if time.present? }
end
다른 예제들과 마찬가지로 이는 클래스 메소드와 유사하게 동작합니다.
class Order < ApplicationRecord
def self.created_before(time)
where(created_at: ...time) if time.present?
end
end
그러나 한 가지 중요한 주의사항이 있습니다: 스코프는 조건문이 false로 평가되더라도 항상 ActiveRecord::Relation 객체를 반환하지만, 클래스 메소드는 nil을 반환합니다. 이는 조건문 중 하나가 false를 반환하는 경우 클래스 메소드를 조건문과 함께 연결할 때 NoMethodError가 발생할 수 있습니다.
13.3 기본 스코프 적용
모델에 대한 모든 쿼리에 스코프가 적용되기를 원한다면 모델 자체 내에서 default_scope 메소드를 사용할 수 있습니다.
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
이 모델에서 쿼리가 실행될 때, SQL 쿼리는 다음과 같이 보일 것입니다:
SELECT * FROM books WHERE (out_of_print = false)
더 복잡한 작업을 수행해야 하는 경우 default_scope를 클래스 메소드로 정의할 수도 있습니다:
class Book < ApplicationRecord
def self.default_scope
# ActiveRecord::Relation을 반환해야 합니다.
end
end
참고: default_scope는 레코드를 생성/빌드할 때 Hash로 스코프 인수가 주어진 경우에도 적용됩니다. 레코드를 업데이트할 때는 적용되지 않습니다. 예:
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
Array 형식으로 주어진 경우 default_scope 쿼리 인수는 기본 속성 할당을 위해 Hash로 변환될 수 없습니다. 예:
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
13.4 스코프 병합
where 절과 마찬가지로 스코프는 AND 조건을 사용하여 병합됩니다.
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where(year_published: 50.years.ago.year..) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
scope와 where 조건을 혼합하여 사용할 수 있으며, 최종 SQL은 모든 조건이 AND로 연결됩니다.
irb> Book.in_print.where(price: ...100)
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
마지막 where 절이 우선되길 원한다면 merge를 사용할 수 있습니다.
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
한 가지 중요한 주의사항은 default_scope가 scope와 where 조건 앞에 추가된다는 것입니다.
```ruby
class Book < ApplicationRecord
default_scope { where(year_published: 50.years.ago.year..) }
scope :in_print, -> { where(out_of_print: false) } scope :out_of_print, -> { where(out_of_print: true) } end ```
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
위에서 볼 수 있듯이 default_scope는 scope와 where 조건에 모두 병합됩니다.
13.5 모든 스코핑 제거
어떤 이유로든 스코핑을 제거하려면 unscoped 메소드를 사용할 수 있습니다. 이는 모델에서 default_scope가 지정되어 있고 특정 쿼리에 적용되지 않아야 할 경우 특히 유용합니다.
Book.unscoped.load
이 메소드는 모든 스코핑을 제거하고 테이블에 대한 일반적인 쿼리를 수행합니다.
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscoped는 블록도 받을 수 있습니다:
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
14 동적 검색기
테이블에서 정의한 각 필드(속성)에 대해 Active Record는 검색기 메소드를 제공합니다. 예를 들어 Customer 모델에 first_name이라는 필드가 있다면 Active Record에서는 find_by_first_name 인스턴스 메소드를 무료로 제공합니다. Customer 모델에 locked 필드도 있다면 find_by_locked 메소드도 제공됩니다.
레코드를 반환하지 않으면 ActiveRecord::RecordNotFound 오류를 발생시키도록 동적 검색기 끝에 느낌표(!)를 지정할 수 있습니다. 예를 들어 Customer.find_by_first_name!("Ryan")과 같이 사용할 수 있습니다.
first_name과 orders_count 두 가지로 검색하려면 필드 사이에 "and"를 입력하여 이러한 검색기를 연결할 수 있습니다. 예를 들어 Customer.find_by_first_name_and_orders_count("Ryan", 5)입니다.
15 Enums
Enum을 사용하면 속성에 대한 값 배열을 정의하고 이름으로 참조할 수 있습니다. 데이터베이스에 저장된 실제 값은 값 중 하나에 매핑된 정수입니다.
Enum을 선언하면 다음이 수행됩니다:
- Enum 값을 가진 또는 가지지 않은 모든 객체를 찾을 수 있는 스코프를 생성합니다.
- 객체가 enum에 대해 특정 값을 가지는지 확인하는 데 사용할 수 있는 인스턴스 메소드를 생성합니다.
- 객체의 enum 값을 변경할 수 있는 인스턴스 메소드를 생성합니다.
enum의 모든 가능한 값에 대해 수행됩니다.
예를 들어 다음 enum 선언이 주어진 경우:
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
다음 스코프가 자동으로 생성되어 status에 대한 특정 값이 있는지 여부에 따라 모든 객체를 찾을 수 있습니다:
irb> Order.shipped
=> #<ActiveRecord::Relation> # status == :shipped인 모든 주문
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # status != :shipped인 모든 주문
다음 인스턴스 메소드가 자동으로 생성되어 모델이 status enum에 대해 해당 값을 가지는지 쿼리합니다:
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
다음 인스턴스 메소드가 자동으로 생성되어 status의 값을 먼저 지정한 다음 상태가 성공적으로 해당 값으로 설정되었는지 쿼리합니다:
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
enum에 대한 자세한 문서는 여기에서 찾을 수 있습니다.
16 메소드 체이닝 이해하기
Active Record 패턴은 메소드 체이닝을 구현하여 여러 Active Record 메소드를 간단하고 직관적인 방식으로 함께 사용할 수 있게 합니다.
이전에 호출한 메소드가 ActiveRecord::Relation을 반환하는 경우에는 all, where, joins와 같은 메소드를 문장에서 연결할 수 있습니다. 단일 객체를 반환하는 메소드(단일 객체 검색 섹션 참조)는 문장의 끝에 있어야 합니다.
아래에는 일부 예시가 있습니다. 이 가이드에서는 모든 가능성을 다루지 않으며 몇 가지 예시만 다룹니다. Active Record 메소드가 호출되면 쿼리가 즉시 생성되어 데이터베이스로 전송되지 않습니다. 데이터가 실제로 필요한 경우에만 쿼리가 전송됩니다. 따라서 아래의 각 예시는 단일 쿼리를 생성합니다.
16.1 여러 테이블에서 필터링된 데이터 검색하기
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
결과는 다음과 같아야 합니다:
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
16.2 여러 테이블에서 특정 데이터 검색
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
위의 코드는 다음과 같이 생성됩니다:
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
참고: 쿼리가 여러 레코드와 일치하는 경우, find_by는 첫 번째 레코드만 가져오고 나머지는 무시합니다 (위의 LIMIT 1 문 참조).
17 객체 찾기 또는 새로운 객체 생성하기
레코드를 찾거나 존재하지 않는 경우 생성해야 하는 경우가 흔합니다. 이를 위해 find_or_create_by 및 find_or_create_by! 메서드를 사용할 수 있습니다.
17.1 find_or_create_by
find_or_create_by 메서드는 지정된 속성을 가진 레코드가 있는지 확인합니다. 레코드가 없는 경우 create가 호출됩니다. 예를 살펴보겠습니다.
"Andy"라는 이름의 고객을 찾고, 없는 경우 생성하려면 다음과 같이 실행할 수 있습니다:
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
이 메서드에 의해 생성된 SQL은 다음과 같습니다:
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_by는 이미 존재하는 레코드나 새로운 레코드 중 하나를 반환합니다. 이 경우에는 이미 "Andy"라는 이름의 고객이 없으므로 레코드가 생성되고 반환됩니다.
새로운 레코드는 데이터베이스에 저장되지 않을 수도 있습니다. 이는 유효성 검사가 통과되었는지 여부에 따라 달라집니다 (마치 create와 같이).
새로운 레코드를 생성할 때 'locked' 속성을 false로 설정하려고 하지만 쿼리에는 포함시키지 않으려고 합니다. 따라서 "Andy"라는 이름의 고객을 찾거나 해당 고객이 존재하지 않는 경우 잠금되지 않은 "Andy"라는 고객을 생성하려고 합니다.
이를 두 가지 방법으로 구현할 수 있습니다. 첫 번째 방법은 create_with를 사용하는 것입니다:
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
두 번째 방법은 블록을 사용하는 것입니다:
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
이 블록은 고객이 생성될 때만 실행됩니다. 이 코드를 두 번째 실행할 때는 블록이 무시됩니다.
17.2 find_or_create_by!
find_or_create_by!를 사용하여 새로운 레코드가 유효하지 않은 경우 예외를 발생시킬 수도 있습니다. 이 가이드에서는 유효성 검사에 대해 다루지 않지만, 일시적으로 다음과 같이 유효성 검사를 추가한다고 가정해 봅시다.
validates :orders_count, presence: true
orders_count를 전달하지 않고 새로운 Customer를 생성하려고 하면 레코드가 유효하지 않으며 예외가 발생합니다:
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can’t be blank
17.3 find_or_initialize_by
find_or_initialize_by 메서드는 find_or_create_by와 동일하게 작동하지만 create 대신 new를 호출합니다. 이는 새로운 모델 인스턴스가 메모리에 생성되지만 데이터베이스에 저장되지 않는다는 것을 의미합니다. find_or_create_by 예제를 계속 사용하여 'Nina'라는 이름의 고객을 찾아보겠습니다:
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
객체가 아직 데이터베이스에 저장되지 않았으므로 생성된 SQL은 다음과 같습니다:
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
데이터베이스에 저장하려면 save를 호출하면 됩니다:
irb> nina.save
=> true
18 SQL로 찾기
테이블에서 레코드를 찾기 위해 직접 SQL을 사용하려면 find_by_sql을 사용할 수 있습니다. find_by_sql 메서드는 기본 쿼리가 단일 레코드를 반환하더라도 객체의 배열을 반환합니다. 예를 들어 다음과 같은 쿼리를 실행할 수 있습니다:
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sql는 데이터베이스에 대한 사용자 정의 호출을 만들고 인스턴스화된 객체를 검색하는 간단한 방법을 제공합니다.
18.1 select_all
find_by_sql에는 connection.select_all이라는 밀접한 관련이 있습니다. select_all은
find_by_sql과 마찬가지로 사용자 정의 SQL을 사용하여 데이터베이스에서 객체를 검색하지만 인스턴스화하지 않습니다.
이 메소드는 ActiveRecord::Result 클래스의 인스턴스를 반환하며 이 객체에 to_a를 호출하면
각 해시가 레코드를 나타내는 해시 배열이 반환됩니다.
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
18.2 pluck
pluck는 현재 관계에서 지정된 열의 값을 선택하는 데 사용될 수 있습니다. 인수로 열 이름의 목록을 받아 해당 열의 값 배열을 반환합니다.
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluck를 사용하면 다음과 같은 코드를 대체할 수 있습니다.
Customer.select(:id).map { |c| c.id }
# 또는
Customer.select(:id).map(&:id)
# 또는
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
다음과 같이:
Customer.pluck(:id)
# 또는
Customer.pluck(:id, :first_name)
pluck는 select와 달리 데이터베이스 결과를 직접 Ruby Array로 변환하며,
ActiveRecord 객체를 생성하지 않습니다. 이는 대량 또는 자주 실행되는 쿼리에 대해 더 나은 성능을 의미할 수 있습니다.
그러나 모델 메소드 재정의는 사용할 수 없습니다. 예를 들어:
class Customer < ApplicationRecord
def name
"I am #{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["I am David", "I am Jeremy", "I am Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
하나의 테이블에서 필드를 쿼리하는 것에 제한되지 않으며, 여러 테이블에서도 쿼리할 수 있습니다.
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
또한 select 및 다른 Relation 스코프와 달리 pluck는 즉시 쿼리를 트리거하므로
더 이상의 스코프와 연결할 수 없지만, 이전에 구성된 스코프와 함께 작동할 수 있습니다.
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
참고: pluck를 사용하면 관계 객체에 include 값이 포함되어 있으면 즉시 로딩이 트리거되며, 쿼리에 필요하지 않더라도 즉시 로딩이 트리거됩니다. 예를 들어:
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
이를 피하는 한 가지 방법은 includes를 unscope하는 것입니다.
irb> assoc.unscope(:includes).pluck(:id)
18.3 pick
pick은 현재 관계에서 지정된 열의 값을 선택하는 데 사용될 수 있습니다. 인수로 열 이름의 목록을 받아 해당 열 값의 첫 번째 행을 반환합니다.
pick은 주로 이미 한 행으로 제한된 관계가 있는 경우 유용한 relation.limit(1).pluck(*column_names).first의 약칭입니다.
pick을 사용하면 다음과 같은 코드를 대체할 수 있습니다.
Customer.where(id: 1).pluck(:id).first
다음과 같이:
Customer.where(id: 1).pick(:id)
18.4 ids
ids는 테이블의 기본 키를 사용하여 관계의 모든 ID를 선택하는 데 사용될 수 있습니다.
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
19 객체의 존재 여부
객체의 존재 여부를 확인하려면 exists?라는 메소드가 있습니다.
이 메소드는 find와 동일한 쿼리를 사용하여 데이터베이스를 조회하지만 객체나 객체 컬렉션 대신 true 또는 false를 반환합니다.
Customer.exists?(1)
exists? 메소드는 여러 값을 사용할 수도 있지만, 그 중 하나라도 레코드가 있는 경우 true를 반환합니다.
Customer.exists?(id: [1, 2, 3])
# 또는
Customer.exists?(first_name: ['Jane', 'Sergei'])
모델이나 관계에서도 인수 없이 exists?를 사용할 수 있습니다.
Customer.where(first_name: 'Ryan').exists?
위의 코드는 first_name이 'Ryan'인 고객이 적어도 하나 있으면 true를 반환하고 그렇지 않으면 false를 반환합니다.
Customer.exists?
위의 코드는 customers 테이블이 비어 있으면 false를 반환하고 그렇지 않으면 true를 반환합니다.
모델이나 관계에서 존재 여부를 확인하기 위해 any?와 many?를 사용할 수도 있습니다. many?는 항목의 존재 여부를 확인하기 위해 SQL count를 사용합니다.
```ruby
모델을 통해
Order.any?
SELECT 1 FROM orders LIMIT 1
Order.many?
SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
네임드 스코프를 통해
Order.shipped.any?
SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
관계를 통해
Book.where(out_of_print: true).any? Book.where(out_of_print: true).many?
연관을 통해
Customer.first.orders.any? Customer.first.orders.many? ```
20 계산
이 섹션은 이 서문에서 예제 메소드로 count를 사용하지만, 설명된 옵션은 모든 하위 섹션에 적용됩니다.
모든 계산 메소드는 모델 자체에서 직접 작동합니다:
irb> Customer.count
SELECT COUNT(*) FROM customers
또는 관계에서 작동할 수도 있습니다:
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
복잡한 계산을 수행하기 위해 관계에서 다양한 판별자 메소드를 사용할 수도 있습니다:
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
이는 다음을 실행합니다:
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
여기서 Order가 enum status: [ :shipped, :being_packed, :cancelled ]를 가지고 있다고 가정합니다.
20.1 count
모델의 테이블에 있는 레코드 수를 확인하려면 Customer.count를 호출하면 숫자가 반환됩니다.
더 구체적으로 하고 데이터베이스에 제목이 있는 모든 고객을 찾으려면 Customer.count(:title)을 사용할 수 있습니다.
옵션에 대해서는 상위 섹션 계산을 참조하십시오.
20.2 average
테이블 중 하나에서 특정 숫자의 평균을 보려면 테이블과 관련된 클래스에 average 메소드를 호출할 수 있습니다. 이 메소드 호출은 다음과 같이 보일 것입니다:
Order.average("subtotal")
이는 필드의 평균 값을 나타내는 숫자 (3.14159265와 같은 부동 소수점 숫자일 수도 있음)를 반환합니다.
옵션에 대해서는 상위 섹션 계산을 참조하십시오.
20.3 minimum
테이블에서 필드의 최소값을 찾으려면 테이블과 관련된 클래스에 minimum 메소드를 호출할 수 있습니다. 이 메소드 호출은 다음과 같이 보일 것입니다:
Order.minimum("subtotal")
옵션에 대해서는 상위 섹션 계산을 참조하십시오.
20.4 maximum
테이블에서 필드의 최대값을 찾으려면 테이블과 관련된 클래스에 maximum 메소드를 호출할 수 있습니다. 이 메소드 호출은 다음과 같이 보일 것입니다:
Order.maximum("subtotal")
옵션에 대해서는 상위 섹션 계산을 참조하십시오.
20.5 sum
테이블의 모든 레코드에 대한 필드의 합계를 찾으려면 테이블과 관련된 클래스에 sum 메소드를 호출할 수 있습니다. 이 메소드 호출은 다음과 같이 보일 것입니다:
Order.sum("subtotal")
옵션에 대해서는 상위 섹션 계산을 참조하십시오.
21 EXPLAIN 실행
관계에 explain을 실행할 수 있습니다. EXPLAIN 출력은 각 데이터베이스마다 다릅니다.
예를 들어, 다음을 실행하는 것은
Customer.where(id: 1).joins(:orders).explain
다음과 같은 결과를 얻을 수 있습니다.
EXPLAIN SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
MySQL과 MariaDB에서는 다릅니다.
Active Record는 해당 데이터베이스 쉘과 유사한 출력을 수행합니다. 따라서 PostgreSQL 어댑터로 실행하는 동일한 쿼리는 다음과 같이 나타납니다.
EXPLAIN SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
Eager loading은 내부에서 하나 이상의 쿼리를 트리거할 수 있으며, 일부 쿼리는 이전 쿼리의 결과가 필요합니다. 따라서 explain은 실제로 쿼리를 실행한 다음 쿼리 계획을 요청합니다. 예를 들어,
ruby
Customer.where(id: 1).includes(:orders).explain
MySQL 및 MariaDB의 경우 다음과 같은 결과를 얻을 수 있습니다:
EXPLAIN SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
PostgreSQL의 경우 다음과 같은 결과를 얻을 수 있습니다:
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
21.1 Explain 옵션
PostgreSQL 및 MySQL을 지원하는 데이터베이스 및 어댑터의 경우, 더 깊은 분석을 제공하기 위해 옵션을 전달할 수 있습니다.
PostgreSQL을 사용하는 경우 다음과 같이 작성하면:
Customer.where(id: 1).joins(:orders).explain(:analyze, :verbose)
다음과 같은 결과를 얻을 수 있습니다:
EXPLAIN (ANALYZE, VERBOSE) SELECT "shop_accounts".* FROM "shop_accounts" INNER JOIN "customers" ON "customers"."id" = "shop_accounts"."customer_id" WHERE "shop_accounts"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.30..16.37 rows=1 width=24) (actual time=0.003..0.004 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Inner Unique: true
-> Index Scan using shop_accounts_pkey on public.shop_accounts (cost=0.15..8.17 rows=1 width=24) (actual time=0.003..0.003 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Index Cond: (shop_accounts.id = '1'::bigint)
-> Index Only Scan using customers_pkey on public.customers (cost=0.15..8.17 rows=1 width=8) (never executed)
Output: customers.id
Index Cond: (customers.id = shop_accounts.customer_id)
Heap Fetches: 0
Planning Time: 0.063 ms
Execution Time: 0.011 ms
(12 rows)
MySQL 또는 MariaDB를 사용하는 경우 다음과 같이 작성하면:
Customer.where(id: 1).joins(:orders).explain(:analyze)
다음과 같은 결과를 얻을 수 있습니다:
ANALYZE SELECT `shop_accounts`.* FROM `shop_accounts` INNER JOIN `customers` ON `customers`.`id` = `shop_accounts`.`customer_id` WHERE `shop_accounts`.`id` = 1
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | r_rows | filtered | r_filtered | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | no matching row in const table |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
1 row in set (0.00 sec)
참고: EXPLAIN 및 ANALYZE 옵션은 MySQL 및 MariaDB 버전에 따라 다를 수 있습니다. (MySQL 5.7, MySQL 8.0, MariaDB)
21.2 EXPLAIN 해석
EXPLAIN의 출력을 해석하는 것은 이 가이드의 범위를 벗어납니다. 다음은 도움이 될 수 있는 몇 가지 지침입니다:
SQLite3: EXPLAIN QUERY PLAN
MySQL: EXPLAIN Output Format
MariaDB: EXPLAIN
PostgreSQL: Using EXPLAIN
피드백
이 가이드의 품질을 개선하는 데 도움을 주시기를 권장합니다.
오타나 사실적인 오류를 발견하면 기여해주십시오. 시작하려면 문서 기여 섹션을 읽어보세요.
불완전한 내용이나 최신 정보가 아닌 내용을 발견할 수도 있습니다. 주요한 부분에 누락된 문서를 추가해주세요. Edge 가이드에서 이미 문제가 해결되었는지 확인하세요. 스타일과 규칙은 Ruby on Rails 가이드 지침을 확인하세요.
수정할 내용을 발견했지만 직접 수정할 수 없는 경우 이슈를 열어주세요.
마지막으로, Ruby on Rails 문서에 관한 모든 토론은 공식 Ruby on Rails 포럼에서 환영합니다.