1 Qu'est-ce que l'interface de requête Active Record ?
Si vous avez l'habitude d'utiliser du SQL brut pour trouver des enregistrements de base de données, vous constaterez généralement qu'il existe de meilleures façons d'effectuer les mêmes opérations dans Rails. Active Record vous protège du besoin d'utiliser SQL dans la plupart des cas.
Active Record effectuera les requêtes sur la base de données pour vous et est compatible avec la plupart des systèmes de base de données, y compris MySQL, MariaDB, PostgreSQL et SQLite. Quel que soit le système de base de données que vous utilisez, le format de méthode Active Record sera toujours le même.
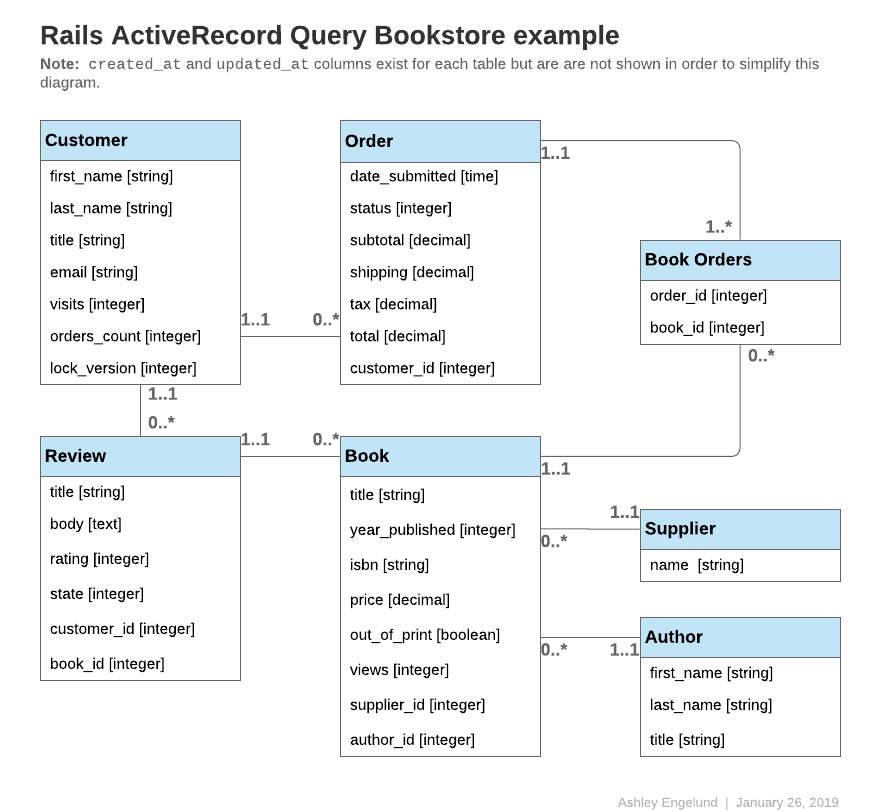
Les exemples de code tout au long de ce guide feront référence à un ou plusieurs des modèles suivants :
CONSEIL : Tous les modèles suivants utilisent id comme clé primaire, sauf indication contraire.
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where(created_at: ...time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
2 Récupération d'objets à partir de la base de données
Pour récupérer des objets à partir de la base de données, Active Record fournit plusieurs méthodes de recherche. Chaque méthode de recherche vous permet de lui passer des arguments pour effectuer certaines requêtes sur votre base de données sans écrire de SQL brut.
Les méthodes sont :
annotatefindcreate_withdistincteager_loadextendingextract_associatedfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetoptimizer_hintsorderpreloadreadonlyreferencesreorderreselectregroupreverse_orderselectwhere
Les méthodes de recherche qui renvoient une collection, comme where et group, renvoient une instance de ActiveRecord::Relation. Les méthodes qui trouvent une seule entité, comme find et first, renvoient une seule instance du modèle.
L'opération principale de Model.find(options) peut être résumée comme suit :
- Convertir les options fournies en une requête SQL équivalente.
- Exécuter la requête SQL et récupérer les résultats correspondants de la base de données.
- Instancier l'objet Ruby équivalent du modèle approprié pour chaque ligne résultante.
- Exécuter les rappels
after_findpuisafter_initialize, le cas échéant.
2.1 Récupération d'un seul objet
Active Record propose plusieurs façons différentes de récupérer un seul objet.
2.1.1 find
En utilisant la méthode find, vous pouvez récupérer l'objet correspondant à la clé primaire spécifiée qui correspond à toutes les options fournies. Par exemple :
# Trouver le client avec la clé primaire (id) 10.
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
La méthode find lèvera une exception ActiveRecord::RecordNotFound si aucun enregistrement correspondant n'est trouvé.
Vous pouvez également utiliser cette méthode pour interroger plusieurs objets. Appelez la méthode find et passez un tableau de clés primaires. Le retour sera un tableau contenant tous les enregistrements correspondants aux clés primaires fournies. Par exemple :
```irb
Trouver les clients avec les clés primaires 1 et 10.
irb> customers = Customer.find([1, 10]) # OU Customer.find(1, 10)
=> [#
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers WHERE (customers.id IN (1,10))
ATTENTION : La méthode find lèvera une exception ActiveRecord::RecordNotFound à moins qu'un enregistrement correspondant ne soit trouvé pour toutes les clés primaires fournies.
2.1.2 take
La méthode take récupère un enregistrement sans aucun ordre implicite. Par exemple :
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers LIMIT 1
La méthode take renvoie nil si aucun enregistrement n'est trouvé et aucune exception ne sera levée.
Vous pouvez passer un argument numérique à la méthode take pour renvoyer jusqu'à ce nombre de résultats. Par exemple :
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers LIMIT 2
La méthode take! se comporte exactement comme take, sauf qu'elle lèvera une exception ActiveRecord::RecordNotFound si aucun enregistrement correspondant n'est trouvé.
CONSEIL : L'enregistrement récupéré peut varier en fonction du moteur de base de données.
2.1.3 first
La méthode first trouve le premier enregistrement trié par clé primaire (par défaut). Par exemple :
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
La méthode first renvoie nil si aucun enregistrement correspondant n'est trouvé et aucune exception ne sera levée.
Si votre portée par défaut contient une méthode de tri, first renverra le premier enregistrement selon cet ordre.
Vous pouvez passer un argument numérique à la méthode first pour renvoyer jusqu'à ce nombre de résultats. Par exemple :
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
Sur une collection triée à l'aide de order, first renverra le premier enregistrement trié par l'attribut spécifié pour order.
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
La méthode first! se comporte exactement comme first, sauf qu'elle lèvera une exception ActiveRecord::RecordNotFound si aucun enregistrement correspondant n'est trouvé.
2.1.4 last
La méthode last trouve le dernier enregistrement trié par clé primaire (par défaut). Par exemple :
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
La méthode last renvoie nil si aucun enregistrement correspondant n'est trouvé et aucune exception ne sera levée.
Si votre portée par défaut contient une méthode de tri, last renverra le dernier enregistrement selon cet ordre.
Vous pouvez passer un argument numérique à la méthode last pour renvoyer jusqu'à ce nombre de résultats. Par exemple :
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
Sur une collection triée à l'aide de order, last renverra le dernier enregistrement trié par l'attribut spécifié pour order.
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
La méthode last! se comporte exactement comme last, sauf qu'elle lèvera une exception ActiveRecord::RecordNotFound si aucun enregistrement correspondant n'est trouvé.
2.1.5 find_by
La méthode find_by trouve le premier enregistrement correspondant à certaines conditions. Par exemple :
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
C'est équivalent à écrire :
Customer.where(first_name: 'Lifo').take
L'équivalent SQL de ce qui précède est :
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
Notez qu'il n'y a pas de ORDER BY dans le SQL ci-dessus. Si vos conditions find_by peuvent correspondre à plusieurs enregistrements, vous devriez appliquer un ordre pour garantir un résultat déterministe.
La méthode find_by! se comporte exactement comme find_by, sauf qu'elle lèvera une exception ActiveRecord::RecordNotFound si aucun enregistrement correspondant n'est trouvé. Par exemple :
irb> Customer.find_by! first_name: 'does not exist'
ActiveRecord::RecordNotFound
Cela équivaut à écrire :
Customer.where(first_name: 'does not exist').take!
2.2 Récupération de plusieurs objets par lots
Nous avons souvent besoin d'itérer sur un grand ensemble d'enregistrements, par exemple lorsque nous envoyons une newsletter à un grand ensemble de clients, ou lorsque nous exportons des données.
Cela peut sembler simple :
# Cela peut consommer trop de mémoire si la table est grande.
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
Mais cette approche devient de plus en plus impraticable à mesure que la taille de la table augmente, car Customer.all.each demande à Active Record de récupérer toute la table en une seule passe, de construire un objet modèle par ligne, puis de conserver l'ensemble du tableau d'objets modèles en mémoire. En effet, si nous avons un grand nombre d'enregistrements, l'ensemble complet peut dépasser la quantité de mémoire disponible.
Rails propose deux méthodes qui résolvent ce problème en divisant les enregistrements en lots adaptés à la mémoire pour le traitement. La première méthode, find_each, récupère un lot d'enregistrements, puis renvoie chaque enregistrement au bloc individuellement en tant que modèle. La deuxième méthode, find_in_batches, récupère un lot d'enregistrements, puis renvoie le lot entier au bloc sous forme d'un tableau de modèles.
CONSEIL : Les méthodes find_each et find_in_batches sont destinées à être utilisées pour le traitement par lots d'un grand nombre d'enregistrements qui ne tiendraient pas en mémoire en une seule fois. Si vous avez juste besoin de parcourir mille enregistrements, les méthodes de recherche régulières sont l'option préférée.
2.2.1 find_each
La méthode find_each récupère les enregistrements par lots, puis renvoie chacun au bloc. Dans l'exemple suivant, find_each récupère les clients par lots de 1000 et les renvoie au bloc un par un :
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
Ce processus est répété, en récupérant plus de lots au besoin, jusqu'à ce que tous les enregistrements aient été traités.
find_each fonctionne sur les classes de modèles, comme on peut le voir ci-dessus, et également sur les relations :
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
tant qu'il n'y a pas d'ordre, car la méthode doit forcer un ordre en interne pour itérer.
Si un ordre est présent dans le récepteur, le comportement dépend du drapeau
config.active_record.error_on_ignored_order. Si la valeur est true, une ArgumentError est
levée, sinon l'ordre est ignoré et un avertissement est émis, ce qui est la
valeur par défaut. Cela peut être outrepassé avec l'option :error_on_ignore, expliquée
ci-dessous.
2.2.1.1 Options pour find_each
:batch_size
L'option :batch_size vous permet de spécifier le nombre d'enregistrements à récupérer dans chaque lot, avant de les passer individuellement au bloc. Par exemple, pour récupérer les enregistrements par lots de 5000 :
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
Par défaut, les enregistrements sont récupérés dans l'ordre croissant de la clé primaire. L'option :start vous permet de configurer le premier ID de la séquence lorsque le plus bas ID n'est pas celui dont vous avez besoin. Cela serait utile, par exemple, si vous vouliez reprendre un processus par lots interrompu, à condition d'avoir enregistré le dernier ID traité comme point de contrôle.
Par exemple, pour envoyer des newsletters uniquement aux clients dont la clé primaire commence à partir de 2000 :
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
Similaire à l'option :start, :finish vous permet de configurer le dernier ID de la séquence lorsque le plus haut ID n'est pas celui dont vous avez besoin.
Cela serait utile, par exemple, si vous vouliez exécuter un processus par lots en utilisant un sous-ensemble d'enregistrements basé sur :start et :finish.
Par exemple, pour envoyer des newsletters uniquement aux clients dont la clé primaire commence à partir de 2000 jusqu'à 10000 :
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
Un autre exemple serait si vous vouliez que plusieurs travailleurs gèrent la même
file de traitement. Vous pourriez faire en sorte que chaque travailleur gère 10000 enregistrements en définissant les options :start et :finish appropriées sur chaque travailleur.
:error_on_ignore
Remplace la configuration de l'application pour spécifier si une erreur doit être levée lorsqu'un ordre est présent dans la relation.
:order
Spécifie l'ordre de la clé primaire (peut être :asc ou :desc). Par défaut, c'est :asc.
ruby
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
2.2.2 find_in_batches
La méthode find_in_batches est similaire à find_each, car les deux récupèrent des lots d'enregistrements. La différence est que find_in_batches renvoie des lots au bloc sous forme d'un tableau de modèles, au lieu de les renvoyer individuellement. L'exemple suivant renverra au bloc fourni un tableau contenant jusqu'à 1000 clients à la fois, le dernier bloc contenant les clients restants :
# Donnez à add_customers un tableau de 1000 clients à la fois.
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batches fonctionne sur les classes de modèles, comme on peut le voir ci-dessus, et également sur les relations :
# Donnez à add_customers un tableau de 1000 clients récemment actifs à la fois.
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
tant qu'ils n'ont pas d'ordre, car la méthode doit forcer un ordre en interne pour itérer.
2.2.2.1 Options pour find_in_batches
La méthode find_in_batches accepte les mêmes options que find_each :
:batch_size
Tout comme pour find_each, batch_size établit combien d'enregistrements seront récupérés dans chaque groupe. Par exemple, récupérer des lots de 2500 enregistrements peut être spécifié comme suit :
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
L'option start permet de spécifier l'ID de début à partir duquel les enregistrements seront sélectionnés. Comme mentionné précédemment, par défaut, les enregistrements sont récupérés dans l'ordre croissant de la clé primaire. Par exemple, pour récupérer les clients à partir de l'ID : 5000 par lots de 2500 enregistrements, le code suivant peut être utilisé :
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
L'option finish permet de spécifier l'ID de fin des enregistrements à récupérer. Le code ci-dessous montre le cas de la récupération des clients par lots, jusqu'au client avec l'ID : 7000 :
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
L'option error_on_ignore remplace la configuration de l'application pour spécifier si une erreur doit être levée lorsqu'un ordre spécifique est présent dans la relation.
3 Conditions
La méthode where vous permet de spécifier des conditions pour limiter les enregistrements renvoyés, représentant la partie WHERE de l'instruction SQL. Les conditions peuvent être spécifiées sous forme de chaîne, de tableau ou de hachage.
3.1 Conditions sous forme de chaîne pure
Si vous souhaitez ajouter des conditions à votre recherche, vous pouvez simplement les spécifier, comme Book.where("title = 'Introduction to Algorithms'"). Cela trouvera tous les livres où la valeur du champ title est 'Introduction to Algorithms'.
AVERTISSEMENT : Construire vos propres conditions sous forme de chaînes pures peut vous rendre vulnérable aux attaques par injection SQL. Par exemple, Book.where("title LIKE '%#{params[:title]}%'") n'est pas sûr. Voir la section suivante pour la méthode préférée pour gérer les conditions à l'aide d'un tableau.
3.2 Conditions sous forme de tableau
Maintenant, que se passe-t-il si ce titre peut varier, par exemple en tant qu'argument provenant d'un endroit quelconque ? La recherche prendrait alors la forme suivante :
Book.where("title = ?", params[:title])
Active Record prendra le premier argument comme chaîne de conditions et tous les arguments supplémentaires remplaceront les points d'interrogation (?) dans celle-ci.
Si vous souhaitez spécifier plusieurs conditions :
Book.where("title = ? AND out_of_print = ?", params[:title], false)
Dans cet exemple, le premier point d'interrogation sera remplacé par la valeur de params[:title] et le second sera remplacé par la représentation SQL de false, qui dépend de l'adaptateur.
Ce code est fortement préférable :
Book.where("title = ?", params[:title])
à ce code :
Book.where("title = #{params[:title]}")
en raison de la sécurité des arguments. Placer la variable directement dans la chaîne de conditions passera la variable à la base de données telle quelle. Cela signifie qu'il s'agira d'une variable non échappée directement d'un utilisateur qui peut avoir de mauvaises intentions. Si vous faites cela, vous mettez toute votre base de données en danger, car une fois qu'un utilisateur découvre qu'il peut exploiter votre base de données, il peut faire à peu près n'importe quoi avec. Ne mettez jamais vos arguments directement à l'intérieur de la chaîne de conditions.
CONSEIL : Pour plus d'informations sur les dangers de l'injection SQL, consultez le Guide de sécurité Ruby on Rails.
3.2.1 Conditions avec des espaces réservés
De la même manière que le style de remplacement (?) des paramètres, vous pouvez également spécifier des clés dans votre chaîne de conditions ainsi qu'un hachage clés/valeurs correspondant :
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
Cela permet une meilleure lisibilité si vous avez un grand nombre de conditions variables.
3.2.2 Conditions utilisant LIKE
Bien que les arguments de condition soient automatiquement échappés pour éviter les injections SQL, les caractères génériques SQL LIKE (c'est-à-dire % et _) ne sont pas échappés. Cela peut entraîner un comportement inattendu si une valeur non filtrée est utilisée dans un argument. Par exemple :
ruby
Book.order(:created_at).order(:title)
This will generate SQL like this:
SELECT * FROM books ORDER BY created_at ASC, title ASC
You can also use the reorder method to replace any existing order with a new one:
Book.order(:created_at).reorder(:title)
This will generate SQL like this:
SELECT * FROM books ORDER BY title ASC
3.3 Limit and Offset
To limit the number of records returned from the database, you can use the limit method. For example, to retrieve the first 5 books:
Book.limit(5)
This will generate SQL like this:
SELECT * FROM books LIMIT 5
To skip a certain number of records and retrieve the rest, you can use the offset method. For example, to retrieve books starting from the 6th record:
Book.offset(5)
This will generate SQL like this:
SELECT * FROM books OFFSET 5
You can also chain limit and offset together:
Book.limit(5).offset(10)
This will generate SQL like this:
SELECT * FROM books LIMIT 5 OFFSET 10
3.4 Combining Conditions
You can combine multiple conditions using the logical operators AND and OR. For example, to find books that are either out of print or have a high rating:
Book.where("out_of_print = ? OR rating > ?", true, 4)
This will generate SQL like this:
SELECT * FROM books WHERE (out_of_print = true OR rating > 4)
You can also use the or method to combine conditions:
Book.where("out_of_print = ?", true).or(Book.where("rating > ?", 4))
This will generate SQL like this:
SELECT * FROM books WHERE (out_of_print = true OR rating > 4)
3.5 Locking Records
Active Record provides a way to lock records in the database to prevent other processes from modifying them. This is useful in scenarios where you want to ensure that a record is not changed while you are working with it.
To lock records, you can use the lock method. For example, to lock a book record:
book = Book.find(1)
book.lock!
This will generate SQL like this:
SELECT * FROM books WHERE books.id = 1 FOR UPDATE
You can also use the lock method directly in a query:
Book.lock.find(1)
This will generate SQL like this:
SELECT * FROM books WHERE books.id = 1 FOR UPDATE
3.6 Conclusion
Active Record provides a powerful and flexible way to query the database using various conditions and ordering options. By understanding these techniques, you can write more efficient and readable code when working with databases in your Ruby applications.
irb
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
ATTENTION: Dans la plupart des systèmes de base de données, lors de la sélection de champs avec distinct à partir d'un ensemble de résultats en utilisant des méthodes telles que select, pluck et ids; la méthode order lèvera une exception ActiveRecord::StatementInvalid à moins que le(s) champ(s) utilisé(s) dans la clause order ne soit inclus dans la liste de sélection. Voir la section suivante pour sélectionner des champs à partir de l'ensemble de résultats.
4 Sélection de champs spécifiques
Par défaut, Model.find sélectionne tous les champs de l'ensemble de résultats en utilisant select *.
Pour sélectionner uniquement un sous-ensemble de champs de l'ensemble de résultats, vous pouvez spécifier le sous-ensemble via la méthode select.
Par exemple, pour sélectionner uniquement les colonnes isbn et out_of_print :
Book.select(:isbn, :out_of_print)
# OU
Book.select("isbn, out_of_print")
La requête SQL utilisée par cet appel à la méthode find sera quelque chose comme :
SELECT isbn, out_of_print FROM books
Soyez prudent car cela signifie également que vous initialisez un objet modèle avec seulement les champs que vous avez sélectionnés. Si vous essayez d'accéder à un champ qui n'est pas dans l'enregistrement initialisé, vous recevrez :
ActiveModel::MissingAttributeError: missing attribute '<attribute>' for Book
Où <attribute> est l'attribut que vous avez demandé. La méthode id ne lèvera pas l'exception ActiveRecord::MissingAttributeError, alors soyez simplement prudent lors de la manipulation des associations car elles ont besoin de la méthode id pour fonctionner correctement.
Si vous souhaitez uniquement récupérer un enregistrement unique par valeur unique dans un certain champ, vous pouvez utiliser distinct :
Customer.select(:last_name).distinct
Cela générera une requête SQL comme celle-ci :
SELECT DISTINCT last_name FROM customers
Vous pouvez également supprimer la contrainte d'unicité :
# Retourne des last_names uniques
query = Customer.select(:last_name).distinct
# Retourne tous les last_names, même s'il y a des doublons
query.distinct(false)
5 Limit et Offset
Pour appliquer la clause LIMIT à la requête SQL générée par Model.find, vous pouvez spécifier la LIMIT en utilisant les méthodes limit et offset sur la relation.
Vous pouvez utiliser limit pour spécifier le nombre d'enregistrements à récupérer, et utiliser offset pour spécifier le nombre d'enregistrements à ignorer avant de commencer à retourner les enregistrements. Par exemple :
Customer.limit(5)
retournera au maximum 5 clients et, comme il ne spécifie aucun décalage, il retournera les 5 premiers de la table. La requête SQL qu'il exécute ressemble à ceci :
SELECT * FROM customers LIMIT 5
En ajoutant offset à cela :
Customer.limit(5).offset(30)
retournera plutôt au maximum 5 clients à partir du 31e. La requête SQL ressemble à ceci :
SELECT * FROM customers LIMIT 5 OFFSET 30
6 Regroupement
Pour appliquer une clause GROUP BY à la requête SQL générée par le finder, vous pouvez utiliser la méthode group.
Par exemple, si vous voulez trouver une collection des dates auxquelles les commandes ont été créées :
Order.select("created_at").group("created_at")
Et cela vous donnera un seul objet Order pour chaque date où il y a des commandes dans la base de données.
La requête SQL qui serait exécutée serait quelque chose comme ceci :
SELECT created_at
FROM orders
GROUP BY created_at
6.1 Total des éléments groupés
Pour obtenir le total des éléments groupés sur une seule requête, appelez count après le group.
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
La requête SQL qui serait exécutée serait quelque chose comme ceci :
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
6.2 Conditions HAVING
SQL utilise la clause HAVING pour spécifier des conditions sur les champs GROUP BY. Vous pouvez ajouter la clause HAVING à la requête SQL générée par Model.find en ajoutant la méthode having à la recherche.
Par exemple :
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
La requête SQL qui serait exécutée serait quelque chose comme ceci :
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
Cela renvoie la date et le prix total pour chaque objet de commande, regroupés par le jour où ils ont été commandés et où le total est supérieur à 200 $.
Vous pouvez accéder au total_price pour chaque objet de commande retourné de cette manière :
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# Retourne le prix total pour le premier objet Order
7 Remplacement des conditions
7.1 unscope
Vous pouvez spécifier certaines conditions à supprimer en utilisant la méthode unscope. Par exemple :
ruby
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
Le SQL qui serait exécuté :
SELECT * FROM books WHERE id > 100 LIMIT 20
-- Requête originale sans `unscope`
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
Vous pouvez également supprimer des clauses where spécifiques. Par exemple, cela supprimera la condition id de la clause where :
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
Une relation qui a utilisé unscope affectera toute relation dans laquelle elle est fusionnée :
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
7.2 only
Vous pouvez également remplacer les conditions à l'aide de la méthode only. Par exemple :
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
Le SQL qui serait exécuté :
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- Requête originale sans `only`
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
7.3 reselect
La méthode reselect remplace une instruction select existante. Par exemple :
Book.select(:title, :isbn).reselect(:created_at)
Le SQL qui serait exécuté :
SELECT books.created_at FROM books
Comparez cela au cas où la clause reselect n'est pas utilisée :
Book.select(:title, :isbn).select(:created_at)
le SQL exécuté serait :
SELECT books.title, books.isbn, books.created_at FROM books
7.4 reorder
La méthode reorder remplace l'ordre de la portée par défaut. Par exemple, si la définition de classe inclut ceci :
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
Et vous exécutez ceci :
Author.find(10).books
Le SQL qui serait exécuté :
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
Vous pouvez utiliser la clause reorder pour spécifier une autre façon d'ordonner les livres :
Author.find(10).books.reorder('year_published ASC')
Le SQL qui serait exécuté :
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
7.5 reverse_order
La méthode reverse_order inverse la clause de tri si elle est spécifiée.
Book.where("author_id > 10").order(:year_published).reverse_order
Le SQL qui serait exécuté :
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
Si aucune clause de tri n'est spécifiée dans la requête, reverse_order trie par la clé primaire dans l'ordre inverse.
Book.where("author_id > 10").reverse_order
Le SQL qui serait exécuté :
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
La méthode reverse_order n'accepte aucun argument.
7.6 rewhere
La méthode [rewhere][] remplace une condition where nommée existante. Par exemple :
Book.where(out_of_print: true).rewhere(out_of_print: false)
Le SQL qui serait exécuté :
SELECT * FROM books WHERE out_of_print = 0
Si la clause rewhere n'est pas utilisée, les clauses where sont combinées avec un AND :
Book.where(out_of_print: true).where(out_of_print: false)
le SQL exécuté serait :
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
7.7 regroup
La méthode regroup remplace une condition group nommée existante. Par exemple :
Book.group(:author).regroup(:id)
Le SQL qui serait exécuté :
SELECT * FROM books GROUP BY id
Si la clause regroup n'est pas utilisée, les clauses group sont combinées :
Book.group(:author).group(:id)
le SQL exécuté serait :
SELECT * FROM books GROUP BY author, id
8 Null Relation
La méthode none renvoie une relation chaînable sans enregistrements. Toute condition ultérieure enchaînée à la relation renvoyée continuera de générer des relations vides. Cela est utile dans les scénarios où vous avez besoin d'une réponse chaînable à une méthode ou une portée qui pourrait renvoyer zéro résultat.
Book.none # renvoie une Relation vide et ne lance aucune requête.
# La méthode highlighted_reviews ci-dessous est censée renvoyer toujours une Relation.
Book.first.highlighted_reviews.average(:rating)
# => Renvoie la note moyenne d'un livre
class Book
# Renvoie les critiques s'il y en a au moins 5,
# sinon considérez cela comme un livre non critiqué
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # Ne répond pas encore au seuil minimum
end
end
end
9 Objets en lecture seule
Active Record fournit la méthode readonly sur une relation pour interdire explicitement la modification de l'un des objets renvoyés. Toute tentative de modifier un enregistrement en lecture seule ne réussira pas et lèvera une exception ActiveRecord::ReadOnlyRecord.
ruby
customer = Customer.readonly.first
customer.visits += 1
customer.save
Comme customer est explicitement défini comme un objet en lecture seule, le code ci-dessus générera une exception ActiveRecord::ReadOnlyRecord lors de l'appel à customer.save avec une valeur mise à jour de visits.
10 Verrouillage des enregistrements pour mise à jour
Le verrouillage est utile pour éviter les conditions de concurrence lors de la mise à jour des enregistrements dans la base de données et garantir des mises à jour atomiques.
Active Record propose deux mécanismes de verrouillage :
- Verrouillage optimiste
- Verrouillage pessimiste
10.1 Verrouillage optimiste
Le verrouillage optimiste permet à plusieurs utilisateurs d'accéder au même enregistrement pour des modifications et suppose un minimum de conflits avec les données. Il le fait en vérifiant si un autre processus a apporté des modifications à un enregistrement depuis son ouverture. Une exception ActiveRecord::StaleObjectError est levée si cela s'est produit et la mise à jour est ignorée.
Colonne de verrouillage optimiste
Pour utiliser le verrouillage optimiste, la table doit avoir une colonne appelée lock_version de type entier. À chaque fois que l'enregistrement est mis à jour, Active Record incrémente la colonne lock_version. Si une demande de mise à jour est effectuée avec une valeur inférieure dans le champ lock_version par rapport à celle actuellement présente dans la colonne lock_version de la base de données, la demande de mise à jour échouera avec une exception ActiveRecord::StaleObjectError.
Par exemple :
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # Lève une exception ActiveRecord::StaleObjectError
Vous êtes alors responsable de la gestion du conflit en capturant l'exception et en annulant, fusionnant ou appliquant autrement la logique métier nécessaire pour résoudre le conflit.
Ce comportement peut être désactivé en définissant ActiveRecord::Base.lock_optimistically = false.
Pour remplacer le nom de la colonne lock_version, ActiveRecord::Base fournit un attribut de classe appelé locking_column :
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
10.2 Verrouillage pessimiste
Le verrouillage pessimiste utilise un mécanisme de verrouillage fourni par la base de données sous-jacente. En utilisant lock lors de la construction d'une relation, un verrou exclusif est obtenu sur les lignes sélectionnées. Les relations utilisant lock sont généralement enveloppées dans une transaction pour éviter les conditions de blocage.
Par exemple :
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, seconde édition'
book.save!
end
La session ci-dessus produit le SQL suivant pour une base de données MySQL :
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, seconde édition' WHERE id = 1
SQL (0.8ms) COMMIT
Vous pouvez également passer du SQL brut à la méthode lock pour autoriser différents types de verrous. Par exemple, MySQL dispose d'une expression appelée LOCK IN SHARE MODE qui vous permet de verrouiller un enregistrement tout en autorisant d'autres requêtes à le lire. Pour spécifier cette expression, il suffit de la passer en tant qu'option de verrouillage :
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
NOTE : Votre base de données doit prendre en charge le SQL brut que vous passez à la méthode lock.
Si vous avez déjà une instance de votre modèle, vous pouvez démarrer une transaction et acquérir le verrou en une seule fois en utilisant le code suivant :
book = Book.first
book.with_lock do
# Ce bloc est appelé dans une transaction,
# le livre est déjà verrouillé.
book.increment!(:views)
end
11 Jointure de tables
Active Record fournit deux méthodes de recherche pour spécifier des clauses JOIN dans le SQL résultant : joins et left_outer_joins.
Alors que joins doit être utilisé pour les INNER JOIN ou les requêtes personnalisées,
left_outer_joins est utilisé pour les requêtes utilisant LEFT OUTER JOIN.
11.1 joins
Il existe plusieurs façons d'utiliser la méthode joins.
11.1.1 Utilisation d'un fragment SQL brut
Vous pouvez simplement fournir le SQL brut spécifiant la clause JOIN à joins :
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
Cela donnera le SQL suivant :
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
11.1.2 Utilisation d'un tableau/d'un hachage d'associations nommées
Active Record vous permet d'utiliser les noms des associations définies sur le modèle comme un raccourci pour spécifier les clauses JOIN pour ces associations lors de l'utilisation de la méthode joins.
Tous les exemples suivants produiront les requêtes de jointure attendues en utilisant INNER JOIN :
11.1.2.1 Jointure d'une seule association
Book.joins(:reviews)
Cela produit :
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
Ou, en français : "retourner un objet Book pour tous les livres avec des critiques". Notez que vous verrez des livres en double si un livre a plus d'une critique. Si vous voulez des livres uniques, vous pouvez utiliser Book.joins(:reviews).distinct.
11.1.3 Joindre plusieurs associations
Book.joins(:author, :reviews)
Cela produit :
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
Ou, en anglais : "retourner tous les livres avec leur auteur qui ont au moins une critique". Notez encore une fois que les livres avec plusieurs critiques apparaîtront plusieurs fois.
11.1.3.1 Joindre des associations imbriquées (niveau unique)
Book.joins(reviews: :customer)
Cela produit :
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
Ou, en anglais : "retourner tous les livres qui ont une critique d'un client".
11.1.3.2 Joindre des associations imbriquées (niveau multiple)
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier])
Cela produit :
SELECT * FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
Ou, en anglais : "retourner tous les auteurs qui ont des livres avec des critiques et qui ont été commandés par un client, et les fournisseurs de ces livres".
11.1.4 Spécifier des conditions sur les tables jointes
Vous pouvez spécifier des conditions sur les tables jointes en utilisant les conditions régulières Array et String. Les conditions de hachage Hash conditions fournissent une syntaxe spéciale pour spécifier des conditions pour les tables jointes :
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
Cela permet de trouver tous les clients qui ont passé des commandes qui ont été créées hier, en utilisant une expression SQL BETWEEN pour comparer created_at.
Une syntaxe alternative et plus propre consiste à imbriquer les conditions de hachage :
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
Pour des conditions plus avancées ou pour réutiliser une portée nommée existante, merge peut être utilisé. Tout d'abord, ajoutons une nouvelle portée nommée au modèle Order :
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
Maintenant, nous pouvons utiliser merge pour fusionner la portée created_in_time_range :
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
Cela permet de trouver tous les clients qui ont passé des commandes qui ont été créées hier, en utilisant à nouveau une expression SQL BETWEEN.
11.2 left_outer_joins
Si vous souhaitez sélectionner un ensemble d'enregistrements qu'ils aient ou non des enregistrements associés, vous pouvez utiliser la méthode left_outer_joins.
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
Ce qui produit :
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
Ce qui signifie : "retourner tous les clients avec leur nombre de critiques, qu'ils aient ou non des critiques".
11.3 where.associated et where.missing
Les méthodes de requête associated et missing vous permettent de sélectionner un ensemble d'enregistrements en fonction de la présence ou de l'absence d'une association.
Pour utiliser where.associated :
Customer.where.associated(:reviews)
Produit :
SELECT customers.* FROM customers
INNER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NOT NULL
Ce qui signifie "retourner tous les clients qui ont fait au moins une critique".
Pour utiliser where.missing :
Customer.where.missing(:reviews)
Produit :
SELECT customers.* FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NULL
Ce qui signifie "retourner tous les clients qui n'ont fait aucune critique".
12 Chargement précoce des associations
Le chargement précoce est le mécanisme permettant de charger les enregistrements associés des objets retournés par Model.find en utilisant le moins de requêtes possible.
12.1 Problème des requêtes N + 1
Considérez le code suivant, qui trouve 10 livres et affiche le nom de famille de leurs auteurs :
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
Ce code semble correct à première vue. Mais le problème réside dans le nombre total de requêtes exécutées. Le code ci-dessus exécute 1 (pour trouver 10 livres) + 10 (une par livre pour charger l'auteur) = 11 requêtes au total.
12.1.1 Solution au problème des requêtes N + 1
Active Record vous permet de spécifier à l'avance toutes les associations qui vont être chargées.
Les méthodes sont :
12.2 includes
Avec includes, Active Record s'assure que toutes les associations spécifiées sont chargées en utilisant le nombre minimal possible de requêtes.
En revisitant le cas ci-dessus en utilisant la méthode includes, nous pourrions réécrire Book.limit(10) pour charger les auteurs de manière précoce :
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
Le code ci-dessus exécutera seulement 2 requêtes, contrairement aux 11 requêtes du cas original :
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
12.2.1 Chargement anticipé de plusieurs associations
Active Record vous permet de charger de manière anticipée un nombre quelconque d'associations avec un seul appel à Model.find en utilisant un tableau, un hachage ou un hachage imbriqué de tableau/hachage avec la méthode includes.
12.2.1.1 Tableau de plusieurs associations
Customer.includes(:orders, :reviews)
Cela charge tous les clients et les commandes et avis associés pour chacun.
12.2.1.2 Hachage d'associations imbriquées
Customer.includes(orders: { books: [:supplier, :author] }).find(1)
Cela trouvera le client avec l'identifiant 1 et chargera de manière anticipée toutes les commandes associées, les livres pour toutes les commandes, et l'auteur et le fournisseur pour chacun des livres.
12.2.2 Spécification de conditions sur les associations chargées de manière anticipée
Bien qu'Active Record vous permette de spécifier des conditions sur les associations chargées de manière anticipée comme avec joins, la méthode recommandée est d'utiliser joins à la place.
Cependant, si vous devez le faire, vous pouvez utiliser where comme vous le feriez normalement.
Author.includes(:books).where(books: { out_of_print: true })
Cela générera une requête qui contient une LEFT OUTER JOIN, tandis que la méthode joins en générera une en utilisant la fonction INNER JOIN à la place.
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN books ON books.author_id = authors.id WHERE (books.out_of_print = 1)
S'il n'y avait pas de condition where, cela générerait l'ensemble normal de deux requêtes.
NOTE : Utiliser where de cette manière ne fonctionnera que lorsque vous lui passerez un hachage. Pour les fragments SQL, vous devez utiliser references pour forcer les tables jointes :
Author.includes(:books).where("books.out_of_print = true").references(:books)
Si, dans le cas de cette requête includes, il n'y avait pas de livres pour aucun auteur, tous les auteurs seraient quand même chargés. En utilisant joins (un INNER JOIN), les conditions de jointure doivent correspondre, sinon aucun enregistrement ne sera renvoyé.
NOTE : Si une association est chargée de manière anticipée dans le cadre d'une jointure, les champs d'une clause de sélection personnalisée ne seront pas présents sur les modèles chargés. Cela est dû à l'ambiguïté quant à savoir s'ils doivent apparaître sur l'enregistrement parent ou l'enfant.
12.3 preload
Avec preload, Active Record charge chaque association spécifiée en utilisant une requête par association.
En revenant sur le problème des requêtes N + 1, nous pourrions réécrire Book.limit(10) pour charger de manière anticipée les auteurs :
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
Le code ci-dessus exécutera seulement 2 requêtes, contrairement aux 11 requêtes du cas original :
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
NOTE : La méthode preload utilise un tableau, un hachage ou un hachage imbriqué de tableau/hachage de la même manière que la méthode includes pour charger un nombre quelconque d'associations avec un seul appel à Model.find. Cependant, contrairement à la méthode includes, il n'est pas possible de spécifier des conditions pour les associations chargées de manière anticipée.
12.4 eager_load
Avec eager_load, Active Record charge toutes les associations spécifiées en utilisant un LEFT OUTER JOIN.
En revenant sur le cas où N + 1 se produisait en utilisant la méthode eager_load, nous pourrions réécrire Book.limit(10) pour charger les auteurs :
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
Le code ci-dessus exécutera seulement 2 requêtes, contrairement aux 11 requêtes du cas original :
SELECT DISTINCT books.id FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id LIMIT 10
SELECT books.id AS t0_r0, books.last_name AS t0_r1, ...
FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id
WHERE books.id IN (1,2,3,4,5,6,7,8,9,10)
NOTE : La méthode eager_load utilise un tableau, un hachage ou un hachage imbriqué de tableau/hachage de la même manière que la méthode includes pour charger un nombre quelconque d'associations avec un seul appel à Model.find. De plus, comme la méthode includes, vous pouvez spécifier des conditions pour les associations chargées de manière anticipée.
12.5 strict_loading
Le chargement anticipé peut éviter les requêtes N + 1, mais il est possible que certaines associations soient toujours chargées de manière paresseuse. Pour vous assurer qu'aucune association n'est chargée de manière paresseuse, vous pouvez activer strict_loading.
En activant le mode de chargement strict sur une relation, une ActiveRecord::StrictLoadingViolationError sera levée si l'enregistrement tente de charger de manière paresseuse une association :
user = User.strict_loading.first
user.comments.to_a # lève une ActiveRecord::StrictLoadingViolationError
13 Scopes
Le scoping vous permet de spécifier des requêtes couramment utilisées qui peuvent être référencées sous forme d'appels de méthode sur les objets d'association ou les modèles. Avec ces scopes, vous pouvez utiliser toutes les méthodes précédemment couvertes telles que where, joins et includes. Tous les corps de scope doivent renvoyer un ActiveRecord::Relation ou nil pour permettre l'appel de méthodes ultérieures (telles que d'autres scopes).
Pour définir un scope simple, nous utilisons la méthode scope à l'intérieur de la classe, en passant la requête que nous souhaitons exécuter lorsque ce scope est appelé :
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
Pour appeler ce scope out_of_print, nous pouvons l'appeler soit sur la classe :
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # tous les livres épuisés
Ou sur une association d'objets Book :
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # tous les livres épuisés de `author`
Les scopes peuvent également être chaînés entre eux :
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
13.1 Passage d'arguments
Votre scope peut prendre des arguments :
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
Appelez le scope comme s'il s'agissait d'une méthode de classe :
irb> Book.costs_more_than(100.10)
Cependant, cela duplique simplement la fonctionnalité qui vous serait fournie par une méthode de classe.
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
Ces méthodes seront toujours accessibles sur les objets d'association :
irb> author.books.costs_more_than(100.10)
13.2 Utilisation de conditionnels
Votre scope peut utiliser des conditionnels :
class Order < ApplicationRecord
scope :created_before, ->(time) { where(created_at: ...time) if time.present? }
end
Comme les autres exemples, cela se comportera de manière similaire à une méthode de classe.
class Order < ApplicationRecord
def self.created_before(time)
where(created_at: ...time) if time.present?
end
end
Cependant, il y a un point important à noter : un scope renverra toujours un objet ActiveRecord::Relation, même si la condition évaluée est false, tandis qu'une méthode de classe renverra nil. Cela peut entraîner une NoMethodError lors de la chaîne de méthodes de classe avec des conditionnels, si l'un des conditionnels renvoie false.
13.3 Application d'un scope par défaut
Si nous souhaitons qu'un scope soit appliqué à toutes les requêtes sur le modèle, nous pouvons utiliser la méthode default_scope à l'intérieur du modèle lui-même.
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
Lorsque des requêtes sont exécutées sur ce modèle, la requête SQL ressemblera maintenant à ceci :
SELECT * FROM books WHERE (out_of_print = false)
Si vous avez besoin de faire des choses plus complexes avec un scope par défaut, vous pouvez également le définir comme une méthode de classe :
class Book < ApplicationRecord
def self.default_scope
# Doit renvoyer un ActiveRecord::Relation.
end
end
REMARQUE : Le default_scope est également appliqué lors de la création/construction d'un enregistrement lorsque les arguments du scope sont donnés sous forme de Hash. Il n'est pas appliqué lors de la mise à jour d'un enregistrement. Par exemple :
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
Sachez que, lorsqu'ils sont donnés au format Array, les arguments de requête de default_scope ne peuvent pas être convertis en Hash pour l'assignation d'attributs par défaut. Par exemple :
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
13.4 Fusion des scopes
Tout comme les clauses where, les scopes sont fusionnés en utilisant des conditions AND.
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where(year_published: 50.years.ago.year..) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
Nous pouvons mélanger et combiner des conditions scope et where et la requête SQL finale aura toutes les conditions jointes avec AND.
irb> Book.in_print.where(price: ...100)
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
Si nous voulons que la dernière clause where l'emporte, alors merge peut être utilisé.
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
Un point important à noter est que le default_scope sera préfixé dans les conditions scope et where.
```ruby
class Book < ApplicationRecord
default_scope { where(year_published: 50.years.ago.year..) }
scope :in_print, -> { where(out_of_print: false) } scope :out_of_print, -> { where(out_of_print: true) } end ```
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
Comme vous pouvez le voir ci-dessus, la default_scope est fusionnée à la fois dans les conditions scope et where.
13.5 Suppression de tous les scopes
Si nous souhaitons supprimer les scopes pour une raison quelconque, nous pouvons utiliser la méthode unscoped. Cela est particulièrement utile si un default_scope est spécifié dans le modèle et ne doit pas être appliqué pour cette requête particulière.
Book.unscoped.load
Cette méthode supprime tous les scopes et effectue une requête normale sur la table.
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscoped peut également accepter un bloc :
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
14 Recherche dynamique
Pour chaque champ (également appelé attribut) que vous définissez dans votre table, Active Record fournit une méthode de recherche. Si vous avez un champ appelé first_name dans votre modèle Customer par exemple, vous obtenez gratuitement la méthode d'instance find_by_first_name d'Active Record. Si vous avez également un champ locked dans le modèle Customer, vous obtenez également la méthode find_by_locked.
Vous pouvez spécifier un point d'exclamation (!) à la fin des finders dynamiques pour les amener à lever une erreur ActiveRecord::RecordNotFound s'ils ne renvoient aucun enregistrement, comme Customer.find_by_first_name!("Ryan")
Si vous souhaitez rechercher à la fois par first_name et orders_count, vous pouvez chaîner ces finders en tapant simplement "and" entre les champs. Par exemple, Customer.find_by_first_name_and_orders_count("Ryan", 5).
15 Enums
Une énumération vous permet de définir un tableau de valeurs pour un attribut et de les référencer par leur nom. La valeur réelle stockée dans la base de données est un entier qui a été mappé sur l'une des valeurs.
La déclaration d'une énumération permet de :
- Créer des scopes qui peuvent être utilisés pour trouver tous les objets qui ont ou n'ont pas une des valeurs de l'énumération
- Créer une méthode d'instance qui peut être utilisée pour déterminer si un objet a une valeur particulière pour l'énumération
- Créer une méthode d'instance qui peut être utilisée pour changer la valeur de l'énumération d'un objet
pour toutes les valeurs possibles d'une énumération.
Par exemple, étant donné cette déclaration enum :
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
Ces scopes sont créés automatiquement et peuvent être utilisés pour trouver tous les objets avec ou sans une valeur particulière pour status :
irb> Order.shipped
=> #<ActiveRecord::Relation> # tous les ordres avec status == :shipped
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # tous les ordres avec status != :shipped
Ces méthodes d'instance sont créées automatiquement et interrogent si le modèle a cette valeur pour l'énumération status :
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
Ces méthodes d'instance sont créées automatiquement et mettront d'abord à jour la valeur de status avec la valeur nommée, puis interrogeront si le statut a été défini avec succès sur la valeur :
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
La documentation complète sur les énumérations peut être trouvée ici.
16 Comprendre le chaînage des méthodes
Le pattern Active Record implémente le chaînage des méthodes, qui nous permet d'utiliser plusieurs méthodes Active Record ensemble de manière simple et directe.
Vous pouvez chaîner des méthodes dans une instruction lorsque la méthode précédente appelée renvoie un ActiveRecord::Relation, comme all, where et joins. Les méthodes qui renvoient un seul objet (voir la section Récupération d'un seul objet) doivent être à la fin de l'instruction.
Voici quelques exemples. Ce guide ne couvrira pas toutes les possibilités, seulement quelques-unes à titre d'exemple. Lorsqu'une méthode Active Record est appelée, la requête n'est pas générée immédiatement et envoyée à la base de données. La requête est envoyée uniquement lorsque les données sont réellement nécessaires. Ainsi, chaque exemple ci-dessous génère une seule requête.
16.1 Récupération de données filtrées à partir de plusieurs tables
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
Le résultat devrait ressembler à ceci:
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
16.2 Récupération de données spécifiques à partir de plusieurs tables
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
Ce qui précède devrait générer:
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
Notez que si une requête correspond à plusieurs enregistrements, find_by ne récupérera que le premier et ignorera les autres (voir l'instruction LIMIT 1 ci-dessus).
17 Trouver ou créer un nouvel objet
Il est courant que vous ayez besoin de trouver un enregistrement ou de le créer s'il n'existe pas. Vous pouvez le faire avec les méthodes find_or_create_by et find_or_create_by!.
17.1 find_or_create_by
La méthode find_or_create_by vérifie si un enregistrement avec les attributs spécifiés existe. Si ce n'est pas le cas, alors create est appelé. Voyons un exemple.
Supposons que vous souhaitiez trouver un client nommé "Andy" et, s'il n'en existe pas, en créer un. Vous pouvez le faire en exécutant:
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
Le SQL généré par cette méthode ressemble à ceci:
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_by renvoie soit l'enregistrement qui existe déjà, soit le nouvel enregistrement. Dans notre cas, nous n'avions pas déjà de client nommé Andy, donc l'enregistrement est créé et renvoyé.
Le nouvel enregistrement peut ne pas être enregistré dans la base de données; cela dépend de la réussite ou non des validations (tout comme create).
Supposons que nous voulions définir l'attribut 'locked' sur false si nous créons un nouvel enregistrement, mais que nous ne voulons pas l'inclure dans la requête. Nous voulons donc trouver le client nommé "Andy" ou, si ce client n'existe pas, créer un client nommé "Andy" qui n'est pas verrouillé.
Nous pouvons y parvenir de deux manières. La première consiste à utiliser create_with:
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
La deuxième façon est d'utiliser un bloc:
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
Le bloc ne sera exécuté que si le client est en cours de création. La deuxième fois que nous exécutons ce code, le bloc sera ignoré.
17.2 find_or_create_by!
Vous pouvez également utiliser find_or_create_by! pour lever une exception si le nouvel enregistrement est invalide. Les validations ne sont pas abordées dans ce guide, mais supposons un instant que vous ajoutiez temporairement
validates :orders_count, presence: true
à votre modèle Customer. Si vous essayez de créer un nouveau Customer sans passer d'orders_count, l'enregistrement sera invalide et une exception sera levée:
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can’t be blank
17.3 find_or_initialize_by
La méthode find_or_initialize_by fonctionnera exactement comme find_or_create_by, mais elle appellera new au lieu de create. Cela signifie qu'une nouvelle instance de modèle sera créée en mémoire mais ne sera pas enregistrée dans la base de données. Poursuivant avec l'exemple de find_or_create_by, nous voulons maintenant le client nommé 'Nina':
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
Parce que l'objet n'est pas encore stocké dans la base de données, le SQL généré ressemble à ceci:
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
Lorsque vous souhaitez l'enregistrer dans la base de données, appelez simplement save:
irb> nina.save
=> true
18 Recherche par SQL
Si vous souhaitez utiliser votre propre SQL pour trouver des enregistrements dans une table, vous pouvez utiliser find_by_sql. La méthode find_by_sql renverra un tableau d'objets même si la requête sous-jacente ne renvoie qu'un seul enregistrement. Par exemple, vous pourriez exécuter cette requête:
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sql vous permet de faire des appels personnalisés à la base de données et de récupérer des objets instanciés.
18.1 select_all
find_by_sql a un proche parent appelé connection.select_all. select_all récupérera
des objets de la base de données en utilisant du SQL personnalisé, tout comme find_by_sql, mais ne les instanciera pas.
Cette méthode renverra une instance de la classe ActiveRecord::Result et en appelant to_a sur cet
objet, vous obtiendrez un tableau de hachages où chaque hachage indique un enregistrement.
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
18.2 pluck
pluck peut être utilisé pour sélectionner la ou les valeurs de la ou des colonnes nommées dans la relation actuelle. Il accepte une liste de noms de colonnes en argument et renvoie un tableau de valeurs des colonnes spécifiées avec le type de données correspondant.
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluck permet de remplacer du code comme :
Customer.select(:id).map { |c| c.id }
# ou
Customer.select(:id).map(&:id)
# ou
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
par :
Customer.pluck(:id)
# ou
Customer.pluck(:id, :first_name)
Contrairement à select, pluck convertit directement un résultat de base de données en un Array Ruby,
sans construire d'objets ActiveRecord. Cela peut entraîner de meilleures performances pour
une requête volumineuse ou fréquemment exécutée. Cependant, toutes les méthodes de modèle substituées ne
seront pas disponibles. Par exemple :
class Customer < ApplicationRecord
def name
"Je suis #{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["Je suis David", "Je suis Jeremy", "Je suis Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
Vous n'êtes pas limité à interroger des champs d'une seule table, vous pouvez également interroger plusieurs tables.
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
De plus, contrairement à select et autres portées de Relation, pluck déclenche une requête immédiate,
et ne peut donc pas être chaîné avec d'autres portées, bien qu'il puisse fonctionner avec
des portées déjà construites précédemment :
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
REMARQUE : Vous devez également savoir que l'utilisation de pluck déclenchera le chargement anticipé si l'objet de relation contient des valeurs d'inclusion, même si le chargement anticipé n'est pas nécessaire pour la requête. Par exemple :
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
Une façon d'éviter cela est de supprimer les inclusions (unscope):
irb> assoc.unscope(:includes).pluck(:id)
18.3 pick
pick peut être utilisé pour sélectionner la ou les valeurs de la ou des colonnes nommées dans la relation actuelle. Il accepte une liste de noms de colonnes en argument et renvoie la première ligne des valeurs de colonne spécifiées avec le type de données correspondant.
pick est un raccourci pour relation.limit(1).pluck(*column_names).first, ce qui est principalement utile lorsque vous avez déjà une relation limitée à une ligne.
pick permet de remplacer du code comme :
Customer.where(id: 1).pluck(:id).first
par :
Customer.where(id: 1).pick(:id)
18.4 ids
ids peut être utilisé pour sélectionner tous les ID de la relation en utilisant la clé primaire de la table.
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
19 Existence des objets
Si vous voulez simplement vérifier l'existence de l'objet, il existe une méthode appelée exists?.
Cette méthode interrogera la base de données en utilisant la même requête que find, mais au lieu de renvoyer un
objet ou une collection d'objets, elle renverra soit true soit false.
Customer.exists?(1)
La méthode exists? accepte également plusieurs valeurs, mais le problème est qu'elle renverra true si l'un
de ces enregistrements existe.
Customer.exists?(id: [1, 2, 3])
# ou
Customer.exists?(first_name: ['Jane', 'Sergei'])
Il est même possible d'utiliser exists? sans arguments sur un modèle ou une relation.
Customer.where(first_name: 'Ryan').exists?
Cela renvoie true s'il y a au moins un client avec le first_name 'Ryan' et false sinon.
Customer.exists?
Cela renvoie false si la table customers est vide et true sinon.
Vous pouvez également utiliser any? et many? pour vérifier l'existence sur un modèle ou une relation. many? utilisera count SQL pour déterminer si l'élément existe.
```ruby
via a model
Order.any?
SELECT 1 FROM orders LIMIT 1
Order.many?
SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
via a named scope
Order.shipped.any?
SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
via a relation
Book.where(out_of_print: true).any? Book.where(out_of_print: true).many?
via an association
Customer.first.orders.any? Customer.first.orders.many? ```
20 Calculs
Cette section utilise count comme méthode exemple dans ce préambule, mais les options décrites s'appliquent à toutes les sous-sections.
Toutes les méthodes de calcul fonctionnent directement sur un modèle :
irb> Customer.count
SELECT COUNT(*) FROM customers
Ou sur une relation :
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
Vous pouvez également utiliser différentes méthodes de recherche sur une relation pour effectuer des calculs complexes :
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
Ce qui exécutera :
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
en supposant que Order a enum status: [ :shipped, :being_packed, :cancelled ].
20.1 count
Si vous voulez voir combien d'enregistrements se trouvent dans la table de votre modèle, vous pouvez appeler Customer.count et cela renverra le nombre.
Si vous voulez être plus précis et trouver tous les clients avec un titre présent dans la base de données, vous pouvez utiliser Customer.count(:title).
Pour les options, veuillez consulter la section parente, Calculs.
20.2 average
Si vous voulez voir la moyenne d'un certain nombre dans l'une de vos tables, vous pouvez appeler la méthode average sur la classe qui se rapporte à la table. Cet appel de méthode ressemblera à ceci :
Order.average("subtotal")
Cela renverra un nombre (éventuellement un nombre à virgule flottante tel que 3.14159265) représentant la valeur moyenne dans le champ.
Pour les options, veuillez consulter la section parente, Calculs.
20.3 minimum
Si vous voulez trouver la valeur minimale d'un champ dans votre table, vous pouvez appeler la méthode minimum sur la classe qui se rapporte à la table. Cet appel de méthode ressemblera à ceci :
Order.minimum("subtotal")
Pour les options, veuillez consulter la section parente, Calculs.
20.4 maximum
Si vous voulez trouver la valeur maximale d'un champ dans votre table, vous pouvez appeler la méthode maximum sur la classe qui se rapporte à la table. Cet appel de méthode ressemblera à ceci :
Order.maximum("subtotal")
Pour les options, veuillez consulter la section parente, Calculs.
20.5 sum
Si vous voulez trouver la somme d'un champ pour tous les enregistrements de votre table, vous pouvez appeler la méthode sum sur la classe qui se rapporte à la table. Cet appel de méthode ressemblera à ceci :
Order.sum("subtotal")
Pour les options, veuillez consulter la section parente, Calculs.
21 Exécution de EXPLAIN
Vous pouvez exécuter explain sur une relation. La sortie EXPLAIN varie pour chaque base de données.
Par exemple, l'exécution de
Customer.where(id: 1).joins(:orders).explain
peut donner
EXPLAIN SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
sous MySQL et MariaDB.
Active Record effectue une jolie impression qui imite celle de la coquille de base de données correspondante. Ainsi, la même requête exécutée avec le adaptateur PostgreSQL donnerait plutôt
EXPLAIN SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
Le chargement précoce peut déclencher plus d'une requête en interne, et certaines requêtes
peut avoir besoin des résultats des précédentes. Pour cette raison, explain en réalité
exécute la requête, puis demande les plans de requête. Par exemple,
ruby
Customer.where(id: 1).includes(:orders).explain
peut donner ceci pour MySQL et MariaDB :
EXPLAIN SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
et peut donner ceci pour PostgreSQL :
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
21.1 Options d'explication
Pour les bases de données et les adaptateurs qui les prennent en charge (actuellement PostgreSQL et MySQL), des options peuvent être passées pour fournir une analyse plus approfondie.
En utilisant PostgreSQL, le code suivant :
Customer.where(id: 1).joins(:orders).explain(:analyze, :verbose)
donne :
EXPLAIN (ANALYZE, VERBOSE) SELECT "shop_accounts".* FROM "shop_accounts" INNER JOIN "customers" ON "customers"."id" = "shop_accounts"."customer_id" WHERE "shop_accounts"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.30..16.37 rows=1 width=24) (actual time=0.003..0.004 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Inner Unique: true
-> Index Scan using shop_accounts_pkey on public.shop_accounts (cost=0.15..8.17 rows=1 width=24) (actual time=0.003..0.003 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Index Cond: (shop_accounts.id = '1'::bigint)
-> Index Only Scan using customers_pkey on public.customers (cost=0.15..8.17 rows=1 width=8) (never executed)
Output: customers.id
Index Cond: (customers.id = shop_accounts.customer_id)
Heap Fetches: 0
Planning Time: 0.063 ms
Execution Time: 0.011 ms
(12 rows)
En utilisant MySQL ou MariaDB, le code suivant :
Customer.where(id: 1).joins(:orders).explain(:analyze)
donne :
ANALYZE SELECT `shop_accounts`.* FROM `shop_accounts` INNER JOIN `customers` ON `customers`.`id` = `shop_accounts`.`customer_id` WHERE `shop_accounts`.`id` = 1
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | r_rows | filtered | r_filtered | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | no matching row in const table |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
1 row in set (0.00 sec)
NOTE : Les options EXPLAIN et ANALYZE varient selon les versions de MySQL et MariaDB. (MySQL 5.7, MySQL 8.0, MariaDB)
21.2 Interprétation de EXPLAIN
L'interprétation de la sortie de EXPLAIN dépasse le cadre de ce guide. Les indications suivantes peuvent être utiles :
SQLite3 : EXPLAIN QUERY PLAN
MySQL : Format de sortie EXPLAIN
MariaDB : EXPLAIN
PostgreSQL : Utilisation de EXPLAIN
Retour d'information
Vous êtes encouragé à contribuer à l'amélioration de la qualité de ce guide.
Veuillez contribuer si vous trouvez des fautes de frappe ou des erreurs factuelles. Pour commencer, vous pouvez lire notre contribution à la documentation section.
Vous pouvez également trouver du contenu incomplet ou des informations qui ne sont pas à jour. Veuillez ajouter toute documentation manquante pour la version principale. Assurez-vous de vérifier Edge Guides d'abord pour vérifier si les problèmes ont déjà été résolus ou non sur la branche principale. Consultez les Directives des guides Ruby on Rails pour le style et les conventions.
Si pour une raison quelconque vous repérez quelque chose à corriger mais ne pouvez pas le faire vous-même, veuillez ouvrir un problème.
Et enfin, toute discussion concernant la documentation de Ruby on Rails est la bienvenue sur le Forum officiel de Ruby on Rails.