1 什麼是 Active Record 查詢介面?
如果您習慣使用原始 SQL 查找資料庫記錄,那麼您通常會發現在 Rails 中有更好的方法執行相同的操作。Active Record 在大多數情況下使您免於使用 SQL。
Active Record 將為您執行資料庫查詢,並與大多數資料庫系統兼容,包括 MySQL、MariaDB、PostgreSQL 和 SQLite。無論您使用哪個資料庫系統,Active Record 的方法格式始終相同。
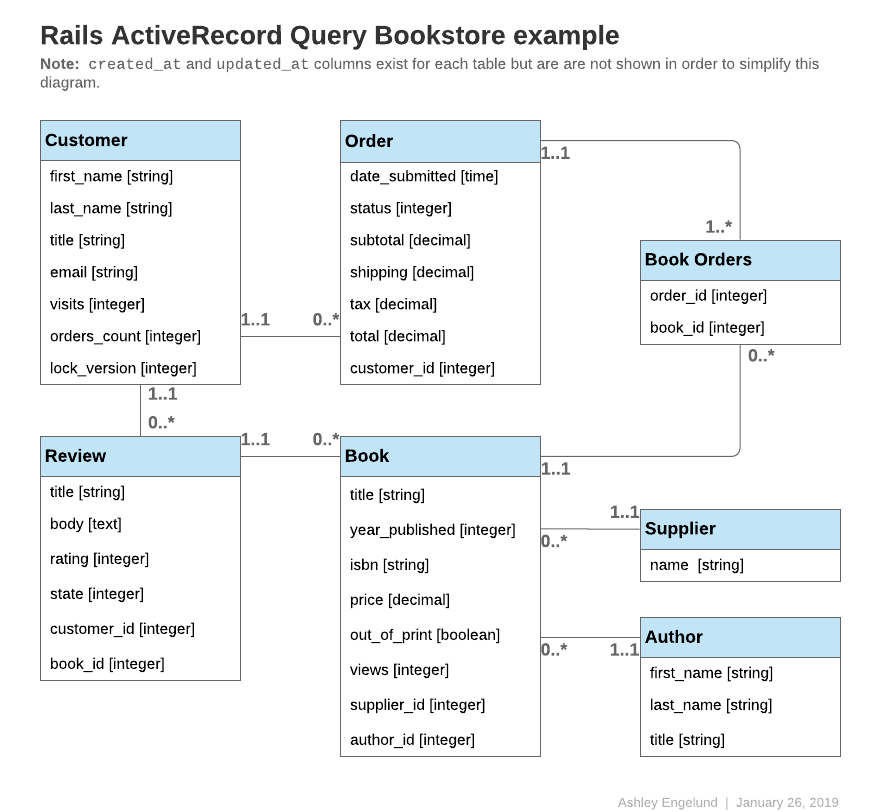
本指南中的程式碼示例將引用以下一個或多個模型:
提示:除非另有指定,以下所有模型都使用 id 作為主鍵。
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where(created_at: ...time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
2 從資料庫擷取物件
要從資料庫擷取物件,Active Record 提供了幾個查詢方法。每個查詢方法都允許您傳入參數,以在不使用原始 SQL 的情況下對資料庫執行特定的查詢。
這些方法包括:
annotatefindcreate_withdistincteager_loadextendingextract_associatedfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetoptimizer_hintsorderpreloadreadonlyreferencesreorderreselectregroupreverse_orderselectwhere
返回集合的查詢方法(例如 where 和 group)將返回 ActiveRecord::Relation 的實例。查找單個實體的方法(例如 find 和 first)將返回模型的單個實例。
Model.find(options)的主要操作可以概括如下:
- 將提供的選項轉換為等效的 SQL 查詢。
- 發出 SQL 查詢並從數據庫檢索相應的結果。
- 為每一行結果實例化適當模型的等效 Ruby 對象。
- 執行
after_find然後是after_initialize回調(如果有)。
2.1 檢索單個對象
Active Record 提供了幾種不同的檢索單個對象的方法。
2.1.1 find
使用 find 方法,您可以檢索與指定的 主鍵 相對應並匹配任何提供的選項的對象。例如:
# 查找主鍵(id)為 10 的客戶。
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
以上的 SQL 等效語句為:
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
如果找不到匹配的記錄,find 方法將引發 ActiveRecord::RecordNotFound 異常。
您還可以使用此方法查詢多個對象。調用 find 方法並傳入一個主鍵數組。返回的將是一個包含所有匹配的記錄的數組,這些記錄與提供的 主鍵 相對應。例如:
# 查找主鍵為 1 和 10 的客戶。
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 10, first_name: "Ryan">]
以上的 SQL 等效語句為:
SELECT * FROM customers WHERE (customers.id IN (1,10))
警告:除非所有提供的主鍵都找到匹配的記錄,否則 find 方法將引發 ActiveRecord::RecordNotFound 異常。
2.1.2 take
take 方法在沒有隱式排序的情況下檢索記錄。例如:
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
以上的 SQL 等效語句為:
SELECT * FROM customers LIMIT 1
如果找不到記錄,take 方法將返回 nil,並且不會引發異常。
您可以將數字參數傳遞給 take 方法,以返回最多該數量的結果。例如
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
以上的 SQL 等效語句為:
SELECT * FROM customers LIMIT 2
take! 方法的行為與 take 完全相同,只是如果找不到匹配的記錄,它將引發 ActiveRecord::RecordNotFound。
提示:檢索的記錄可能因數據庫引擎而異。
2.1.3 first
first 方法按照主鍵(默認)順序查找第一條記錄。例如:
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
以上的 SQL 等效語句為:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
如果找不到匹配的記錄,first 方法將返回 nil,並且不會引發異常。
如果您的默認作用域包含一個 order 方法,first 將根據此排序返回第一條記錄。
您可以將數字參數傳遞給 first 方法,以返回最多該數量的結果。例如
irb
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
上述的 SQL 等價語句為:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
在使用 order 排序的集合上,first 方法將返回按指定屬性進行排序的第一條記錄。
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
上述的 SQL 等價語句為:
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
first! 方法的行為與 first 完全相同,只是如果找不到匹配的記錄,它將引發 ActiveRecord::RecordNotFound 錯誤。
2.1.4 last
last 方法查找按主鍵(默認)排序的最後一條記錄。例如:
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
上述的 SQL 等價語句為:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
如果找不到匹配的記錄,last 方法將返回 nil,並且不會引發異常。
如果您的默認範圍包含一個 order 方法,last 將根據此排序返回最後一條記錄。
您可以將數字參數傳遞給 last 方法,以返回最多該數量的結果。例如:
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
上述的 SQL 等價語句為:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
在使用 order 排序的集合上,last 方法將返回按指定屬性進行排序的最後一條記錄。
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
上述的 SQL 等價語句為:
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
last! 方法的行為與 last 完全相同,只是如果找不到匹配的記錄,它將引發 ActiveRecord::RecordNotFound 錯誤。
2.1.5 find_by
find_by 方法查找與某些條件匹配的第一條記錄。例如:
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
等價於以下寫法:
Customer.where(first_name: 'Lifo').take
上述的 SQL 等價語句為:
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
請注意,上述 SQL 中沒有 ORDER BY。如果您的 find_by 條件可以匹配多條記錄,您應該應用排序以確保結果的確定性。
find_by! 方法的行為與 find_by 完全相同,只是如果找不到匹配的記錄,它將引發 ActiveRecord::RecordNotFound 錯誤。例如:
irb> Customer.find_by! first_name: 'does not exist'
ActiveRecord::RecordNotFound
這等價於以下寫法:
Customer.where(first_name: 'does not exist').take!
2.2 批量檢索多個對象
我們經常需要遍歷一個大型記錄集,例如向一個大型客戶集合發送通訊,或者導出數據。
這可能看起來很簡單:
# 如果表很大,這可能會消耗太多內存。
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
但是隨著表格大小的增加,這種方法變得越來越不實用,因為 Customer.all.each 指示 Active Record 在一次遍歷中擷取整個表格,為每一行建立一個模型物件,然後將整個模型物件陣列保存在記憶體中。事實上,如果我們有大量的記錄,整個集合可能會超過可用的記憶體量。
Rails 提供了兩種方法來解決這個問題,將記錄分成適合記憶體的批次進行處理。第一種方法是 find_each,它擷取一批記錄,然後將每個記錄作為模型物件逐個傳遞給區塊。第二種方法是 find_in_batches,它擷取一批記錄,然後將整個批次作為模型物件陣列傳遞給區塊。
提示:find_each 和 find_in_batches 方法用於批次處理大量記錄,這些記錄無法一次全部放入記憶體中。如果只需要遍歷一千條記錄,則常規的查詢方法是首選選項。
2.2.1 find_each
find_each 方法以批次擷取記錄,然後將每個記錄作為模型物件逐個傳遞給區塊。在下面的示例中,find_each 每次以1000條記錄為一批擷取客戶記錄,並將它們逐個傳遞給區塊:
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
這個過程會重複進行,根據需要擷取更多批次,直到處理完所有記錄。
find_each 可以用於模型類,如上所示,也可以用於關聯:
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
只要它們沒有排序,因為該方法需要在內部強制排序以進行迭代。
如果接收者中存在排序,則行為取決於標誌 config.active_record.error_on_ignored_order。如果為 true,則會引發 ArgumentError,否則將忽略排序並發出警告,這是默認行為。可以使用選項 :error_on_ignore 覆蓋此行為,下面會解釋。
2.2.1.1 find_each 的選項
:batch_size
:batch_size 選項允許您指定每批擷取的記錄數,在傳遞給區塊之前。例如,要以每批5000條記錄擷取記錄:
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
預設情況下,記錄按照主鍵的升序擷取。:start 選項允許您在最低 ID 不是您需要的 ID 時配置序列的第一個 ID。例如,如果您想要恢復中斷的批次處理,並且保存了最後處理的 ID 作為檢查點,這將非常有用。
例如,只向從2000開始的主鍵的客戶發送新聞通訊:
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
與 :start 選項類似,:finish 允許您在最高 ID 不是您需要的 ID 時配置序列的最後一個 ID。這將非常有用,例如,如果您想要使用基於 :start 和 :finish 的子集記錄運行批次處理。
例如,只向從2000開始到10000的主鍵的客戶發送新聞通訊:
ruby
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
另一個例子是如果你想要多個工作程序處理相同的處理佇列。你可以通過在每個工作程序上設置適當的 :start 和 :finish 選項,使每個工作程序處理 10000 條記錄。
:error_on_ignore
覆蓋應用程序配置以指定在關聯中存在訂單時是否應該引發錯誤。
:order
指定主鍵順序(可以是 :asc 或 :desc)。默認為 :asc。
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
2.2.2 find_in_batches
find_in_batches 方法與 find_each 類似,因為它們都檢索記錄的批次。不同之處在於 find_in_batches 將批次作為模型數組傳遞給塊,而不是逐個傳遞。下面的示例將一次向提供的塊傳遞一個包含最多 1000 個客戶的數組,最後一個塊包含任何剩餘的客戶:
# 每次給 add_customers 一個包含 1000 個客戶的數組。
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batches 可以在模型類上使用,如上所示,也可以在關聯上使用:
# 每次給 add_customers 一個包含 1000 個最近活躍客戶的數組。
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
只要它們沒有排序,因為該方法需要在內部強制設置一個順序來進行迭代。
2.2.2.1 find_in_batches 的選項
find_in_batches 方法接受與 find_each 相同的選項:
:batch_size
與 find_each 一樣,batch_size 確定每個組中將檢索多少條記錄。例如,可以指定檢索 2500 條記錄的批次:
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
start 選項允許指定從哪個 ID 開始選擇記錄。如前所述,默認情況下,按照主鍵的升序獲取記錄。例如,要檢索從 ID: 5000 開始的客戶,每次檢索 2500 條記錄,可以使用以下代碼:
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
finish 選項允許指定要檢索的記錄的結束 ID。下面的代碼顯示了以批次方式檢索客戶,直到 ID: 7000 的客戶:
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
error_on_ignore 選項覆蓋應用程序配置,以指定在關聯中存在特定順序時是否應該引發錯誤。
3 條件
where 方法允許您指定限制返回的記錄的條件,表示 SQL 語句的 WHERE 部分。條件可以指定為字符串、數組或哈希的形式。
3.1 純字符串條件
如果您想要添加條件到您的查詢中,您可以直接在其中指定它們,就像 Book.where("title = 'Introduction to Algorithms'") 一樣。這將找到所有 title 字段值為 'Introduction to Algorithms' 的書籍。
警告:使用純字符串構建自己的條件可能會使您容易受到 SQL 注入攻擊。例如,Book.where("title LIKE '%#{params[:title]}%'") 是不安全的。請參閱下一節,了解使用數組處理條件的首選方法。
3.2 數組條件
現在,如果標題可以變化,例如作為某個地方的參數,則查詢將如下所示:
Book.where("title = ?", params[:title])
Active Record將第一個參數作為條件字符串,任何額外的參數將替換其中的問號(?)。
如果您想指定多個條件:
Book.where("title = ? AND out_of_print = ?", params[:title], false)
在此示例中,第一個問號將被params[:title]的值替換,第二個問號將被false的SQL表示替換,具體取決於適配器。
這段代碼非常推薦使用:
Book.where("title = ?", params[:title])
而不是這段代碼:
Book.where("title = #{params[:title]}")
因為它具有參數的安全性。將變量直接放入條件字符串中將將變量原樣傳遞給數據庫。這意味著它將是來自可能具有惡意意圖的用戶的未經轉義的變量。如果這樣做,您將使整個數據庫面臨風險,因為一旦用戶發現他們可以利用您的數據庫,他們可以對其進行任何操作。絕對不要將參數直接放在條件字符串中。
提示:有關SQL注入的危險性的更多信息,請參閱Ruby on Rails安全指南。
3.2.1 佔位符條件
與參數的(?)替換風格類似,您還可以在條件字符串中指定鍵,以及相應的鍵/值哈希:
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
如果您有大量的變量條件,這將使代碼更易讀。
3.2.2 使用LIKE的條件
雖然條件參數會自動進行轉義以防止SQL注入,但SQL的LIKE通配符(即%,_)不會進行轉義。如果在參數中使用未經過濾的值,可能會導致意外的行為。例如:
Book.where("title LIKE ?", params[:title] + "%")
在上面的代碼中,意圖是匹配以用戶指定的字符串開頭的標題。但是,params[:title]中的任何%或_都將被視為通配符,導致意外的查詢結果。在某些情況下,這也可能阻止數據庫使用預期的索引,從而導致查詢速度變慢。
為了避免這些問題,在參數的相應部分中使用sanitize_sql_like來轉義通配符字符:
Book.where("title LIKE ?",
Book.sanitize_sql_like(params[:title]) + "%")
3.3 哈希條件
Active Record還允許您傳遞哈希條件,這可以增加條件語法的可讀性。使用哈希條件,您可以傳遞一個哈希,其中鍵是您想要限定的字段,值是您想要如何限定它們的方式:
注意:只有相等性、範圍和子集檢查可以使用哈希條件。
3.3.1 相等條件
Book.where(out_of_print: true)
這將生成以下SQL:
SELECT * FROM books WHERE (books.out_of_print = 1)
字段名也可以是字符串:
Book.where('out_of_print' => true)
在屬於關係的情況下,如果使用Active Record對象作為值,則可以使用關聯鍵來指定模型。此方法也適用於多態關係。
ruby
author = Author.first
Book.where(author: author)
Author.joins(:books).where(books: { author: author })
3.3.2 範圍條件
Book.where(created_at: (Time.now.midnight - 1.day)..Time.now.midnight)
這將通過使用 BETWEEN SQL 語句找到昨天創建的所有書籍:
SELECT * FROM books WHERE (books.created_at BETWEEN '2008-12-21 00:00:00' AND '2008-12-22 00:00:00')
這展示了 陣列條件 中示例的簡潔語法。
支援無起點和無終點的範圍,可用於構建小於/大於的條件。
Book.where(created_at: (Time.now.midnight - 1.day)..)
這將生成如下的 SQL:
SELECT * FROM books WHERE books.created_at >= '2008-12-21 00:00:00'
3.3.3 子集條件
如果你想使用 IN 表達式查找記錄,可以將陣列傳遞給條件哈希:
Customer.where(orders_count: [1, 3, 5])
這段代碼將生成如下的 SQL:
SELECT * FROM customers WHERE (customers.orders_count IN (1,3,5))
3.4 NOT 條件
可以通過 where.not 構建 NOT SQL 查詢:
Customer.where.not(orders_count: [1, 3, 5])
換句話說,可以通過調用 where 而不帶參數,然後立即鏈接 not 並傳遞 where 條件來生成此查詢。這將生成如下的 SQL:
SELECT * FROM customers WHERE (customers.orders_count NOT IN (1,3,5))
如果查詢在可為空的列上具有哈希條件且非空值,則具有可為空的列上的 nil 值的記錄將不會被返回。例如:
Customer.create!(nullable_country: nil)
Customer.where.not(nullable_country: "UK")
=> []
# 但是
Customer.create!(nullable_country: "UK")
Customer.where.not(nullable_country: nil)
=> [#<Customer id: 2, nullable_country: "UK">]
3.5 OR 條件
兩個關聯之間的 OR 條件可以通過在第一個關聯上調用 or,並將第二個關聯作為參數傳遞來構建。
Customer.where(last_name: 'Smith').or(Customer.where(orders_count: [1, 3, 5]))
SELECT * FROM customers WHERE (customers.last_name = 'Smith' OR customers.orders_count IN (1,3,5))
3.6 AND 條件
可以通過鏈接 where 條件來構建 AND 條件。
Customer.where(last_name: 'Smith').where(orders_count: [1, 3, 5])
SELECT * FROM customers WHERE customers.last_name = 'Smith' AND customers.orders_count IN (1,3,5)
可以通過在第一個關聯上調用 and,並將第二個關聯作為參數傳遞來構建關聯之間的邏輯交集的 AND 條件。
Customer.where(id: [1, 2]).and(Customer.where(id: [2, 3]))
SELECT * FROM customers WHERE (customers.id IN (1, 2) AND customers.id IN (2, 3))
4 排序
要按特定順序從數據庫檢索記錄,可以使用 order 方法。
例如,如果你正在獲取一組記錄並希望按表中的 created_at 字段按升序排序:
Book.order(:created_at)
# 或者
Book.order("created_at")
你也可以指定 ASC 或 DESC:
Book.order(created_at: :desc)
# 或者
Book.order(created_at: :asc)
# 或者
Book.order("created_at DESC")
# 或者
Book.order("created_at ASC")
或按多個字段排序:
Book.order(title: :asc, created_at: :desc)
# 或者
Book.order(:title, created_at: :desc)
# 或者
Book.order("title ASC, created_at DESC")
# 或者
Book.order("title ASC", "created_at DESC")
如果要多次調用 order,後續的排序將附加到第一個排序:
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
警告:在大多數資料庫系統中,使用select、pluck和ids等方法從結果集中選擇具有distinct的字段時,除非order子句中使用的字段包含在選擇列表中,否則order方法將引發ActiveRecord::StatementInvalid異常。請參閱下一節以選擇結果集中的字段。
5 選擇特定字段
默認情況下,Model.find使用select *從結果集中選擇所有字段。
要從結果集中僅選擇一個子集的字段,可以通過select方法指定該子集。
例如,只選擇isbn和out_of_print列:
Book.select(:isbn, :out_of_print)
# 或者
Book.select("isbn, out_of_print")
此查詢語句的SQL查詢將類似於:
SELECT isbn, out_of_print FROM books
請注意,這也意味著您只使用選擇的字段來初始化模型對象。如果您嘗試訪問未初始化記錄中不存在的字段,將收到以下錯誤:
ActiveModel::MissingAttributeError: missing attribute '<attribute>' for Book
其中<attribute>是您要求的屬性。id方法不會引發ActiveRecord::MissingAttributeError,因此在處理關聯時要小心,因為它們需要id方法才能正常工作。
如果您只想在某個字段的每個唯一值中抓取一條記錄,可以使用distinct:
Customer.select(:last_name).distinct
這將生成類似於以下的SQL語句:
SELECT DISTINCT last_name FROM customers
您還可以刪除唯一性約束:
# 返回唯一的last_names
query = Customer.select(:last_name).distinct
# 返回所有的last_names,即使有重複的
query.distinct(false)
6 限制和偏移
要對Model.find發出的SQL應用LIMIT,可以在關聯上使用limit和offset方法指定LIMIT。
您可以使用limit指定要檢索的記錄數,使用offset指定在開始返回記錄之前要跳過的記錄數。例如
Customer.limit(5)
將返回最多5個客戶,因為它未指定偏移量,它將返回表中的前5個。它執行的SQL如下:
SELECT * FROM customers LIMIT 5
在此基礎上添加offset
Customer.limit(5).offset(30)
將返回從第31個開始的最多5個客戶。SQL如下:
SELECT * FROM customers LIMIT 5 OFFSET 30
7 分組
要對查找器發出的SQL應用GROUP BY子句,可以使用group方法。
例如,如果您想查找訂單創建日期的集合:
Order.select("created_at").group("created_at")
這將為數據庫中存在訂單的每個日期返回一個單獨的Order對象。
執行的SQL語句將類似於:
SELECT created_at
FROM orders
GROUP BY created_at
7.1 分組項目的總數
要在單個查詢中獲取分組項目的總數,請在group之後調用count。
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
執行的 SQL 如下所示:
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
7.2 HAVING 條件
SQL 使用 HAVING 子句來指定對 GROUP BY 欄位的條件。您可以通過在查詢中添加 having 方法來將 HAVING 子句添加到 Model.find 所執行的 SQL 中。
例如:
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
執行的 SQL 如下所示:
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
這將返回每個訂單物件的日期和總價,按照它們下單的日期分組,並且總價超過 200 美元。
您可以像這樣訪問每個返回的訂單物件的 total_price:
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# 返回第一個 Order 物件的總價
8 覆蓋條件
8.1 unscope
您可以使用 unscope 方法指定要刪除的特定條件。例如:
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
執行的 SQL:
SELECT * FROM books WHERE id > 100 LIMIT 20
-- 沒有 `unscope` 的原始查詢
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
您還可以取消特定的 where 子句。例如,這將從 where 子句中刪除 id 條件:
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
使用 unscope 的關聯將影響合併到其中的任何關聯:
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
8.2 only
您還可以使用 only 方法覆蓋條件。例如:
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
執行的 SQL:
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- 沒有 `only` 的原始查詢
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
8.3 reselect
reselect 方法覆蓋現有的 select 語句。例如:
Book.select(:title, :isbn).reselect(:created_at)
執行的 SQL:
SELECT books.created_at FROM books
與不使用 reselect 子句的情況進行比較:
Book.select(:title, :isbn).select(:created_at)
執行的 SQL:
SELECT books.title, books.isbn, books.created_at FROM books
8.4 reorder
reorder 方法覆蓋默認的排序方式。例如,如果類定義中包含以下內容:
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
並且執行以下代碼:
Author.find(10).books
執行的 SQL:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
您可以使用 reorder 子句指定不同的排序方式:
Author.find(10).books.reorder('year_published ASC')
執行的 SQL:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
8.5 reverse_order
reverse_order 方法會反轉指定的排序子句。
Book.where("author_id > 10").order(:year_published).reverse_order
執行的 SQL:
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
如果查詢中沒有指定排序子句,則 reverse_order 會按照主鍵的反向順序進行排序。
Book.where("author_id > 10").reverse_order
執行的 SQL:
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
reverse_order 方法不接受任何參數。
8.6 rewhere
[rewhere][] 方法會覆蓋現有的 where 條件。例如:
Book.where(out_of_print: true).rewhere(out_of_print: false)
執行的 SQL:
SELECT * FROM books WHERE out_of_print = 0
如果不使用 rewhere 子句,則 where 條件會進行 AND 連接:
Book.where(out_of_print: true).where(out_of_print: false)
執行的 SQL:
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
8.7 regroup
regroup 方法會覆蓋現有的 group 條件。例如:
Book.group(:author).regroup(:id)
執行的 SQL:
SELECT * FROM books GROUP BY id
如果不使用 regroup 子句,則 group 條件會合併在一起:
Book.group(:author).group(:id)
執行的 SQL:
SELECT * FROM books GROUP BY author, id
9 空關聯
none 方法返回一個可鏈接的關聯,其中沒有記錄。返回的關聯後續鏈接的任何條件都將繼續生成空關聯。這在需要對可能返回零結果的方法或作用域進行鏈接回應時非常有用。
Book.none # 返回一個空的關聯並且不執行任何查詢。
# 下面的 highlighted_reviews 方法預期始終返回一個關聯。
Book.first.highlighted_reviews.average(:rating)
# => 返回一本書的平均評分
class Book
# 如果有至少 5 個評論,則返回評論,
# 否則將其視為未評論的書籍
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # 尚未達到最低閾值
end
end
end
10 只讀對象
Active Record 在關聯上提供了 readonly 方法,以明確禁止修改返回的任何對象。任何嘗試修改只讀記錄的操作都將失敗,並引發 ActiveRecord::ReadOnlyRecord 異常。
customer = Customer.readonly.first
customer.visits += 1
customer.save
由於 customer 被明確設置為只讀對象,上面的代碼在調用 customer.save 時,使用更新後的 visits 值將引發 ActiveRecord::ReadOnlyRecord 異常。
11 鎖定記錄以進行更新
鎖定對於防止數據庫中的記錄更新時的競爭條件非常有用,並確保原子更新。
Active Record 提供了兩種鎖定機制:
- 樂觀鎖定
- 悲觀鎖定
11.1 樂觀鎖定
樂觀鎖定允許多個用戶訪問同一條記錄進行編輯,並假設數據的衝突最少。它通過檢查是否有其他進程在打開記錄後對其進行了更改來實現。如果發生這種情況,將拋出 ActiveRecord::StaleObjectError 異常,並忽略更新。
樂觀鎖定列
為了使用樂觀鎖定,表格需要有一個名為 lock_version 的整數類型列。每次記錄更新時,Active Record 會增加 lock_version 列的值。如果更新請求中的 lock_version 字段的值低於數據庫中 lock_version 列的值,則更新請求將失敗並引發 ActiveRecord::StaleObjectError。
例如:
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # 引發 ActiveRecord::StaleObjectError
然後,您需要通過捕獲異常並回滾、合併或以其他方式應用解決衝突所需的業務邏輯來處理衝突。
可以通過設置 ActiveRecord::Base.lock_optimistically = false 來關閉此行為。
要覆蓋 lock_version 列的名稱,ActiveRecord::Base 提供了一個名為 locking_column 的類屬性:
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
11.2 悲觀鎖定
悲觀鎖定使用底層數據庫提供的鎖定機制。在構建關聯時使用 lock 會對所選行獲取獨占鎖定。通常,使用 lock 的關聯會在事務中進行包裹,以防止死鎖條件。
例如:
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, second edition'
book.save!
end
上述會話對於 MySQL 數據庫生成以下 SQL:
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, second edition' WHERE id = 1
SQL (0.8ms) COMMIT
您還可以將原始 SQL 傳遞給 lock 方法,以允許不同類型的鎖定。例如,MySQL 有一個名為 LOCK IN SHARE MODE 的表達式,您可以鎖定一條記錄,但仍允許其他查詢讀取它。只需將其作為鎖定選項傳遞給 lock 方法即可指定此表達式:
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
注意:您的數據庫必須支持您傳遞給 lock 方法的原始 SQL。
如果已經有模型的實例,可以使用以下代碼一次性開始事務並獲取鎖定:
book = Book.first
book.with_lock do
# 此塊在事務中調用,
# book 已經被鎖定。
book.increment!(:views)
end
12 連接表格
Active Record 提供了兩個查找方法,用於在生成的 SQL 中指定 JOIN 子句:joins 和 left_outer_joins。
雖然 joins 應該用於 INNER JOIN 或自定義查詢,left_outer_joins 用於使用 LEFT OUTER JOIN 的查詢。
12.1 joins
有多種使用 joins 方法的方式。
12.1.1 使用字符串 SQL 片段
您可以直接提供指定 JOIN 子句的原始 SQL 給 joins:
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
這將生成以下 SQL:
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
12.1.2 使用命名關聯的數組/哈希
Active Record 允許您在使用 joins 方法時,使用模型上定義的關聯的名稱作為指定這些關聯的 JOIN 子句的捷徑。
以下所有使用INNER JOIN的查詢都會產生預期的連接查詢:
12.1.2.1 連接單一關聯
Book.joins(:reviews)
這會產生:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
或者,用中文來說:"返回所有具有評論的書籍對象"。請注意,如果一本書有多個評論,則會看到重複的書籍。如果要獲取唯一的書籍,可以使用Book.joins(:reviews).distinct。
12.1.2.2 連接多個關聯
Book.joins(:author, :reviews)
這會產生:
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
或者,用中文來說:"返回所有具有至少一個評論的書籍及其作者"。再次注意,具有多個評論的書籍會顯示多次。
12.1.2.3 連接嵌套關聯(單層)
Book.joins(reviews: :customer)
這會產生:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
或者,用中文來說:"返回所有具有由客戶評論的書籍"。
12.1.2.4 連接嵌套關聯(多層)
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier])
這會產生:
SELECT * FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
或者,用中文來說:"返回所有具有評論的書籍的作者,並且這些書籍已被客戶訂購,以及這些書籍的供應商"。
12.1.3 在連接的表上指定條件
您可以使用常規的數組條件和字符串條件在連接的表上指定條件。哈希條件提供了一種特殊的語法來指定連接的表的條件:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
這將查找所有昨天創建的訂單的客戶,使用BETWEEN SQL表達式來比較created_at。
另一種更簡潔的語法是嵌套哈希條件:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
對於更高級的條件或重用現有的命名作用域,可以使用merge。首先,讓我們在Order模型中添加一個新的命名作用域:
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
現在,我們可以使用merge將created_in_time_range作用域合併進來:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
這將查找所有昨天創建的訂單的客戶,再次使用BETWEEN SQL表達式。
12.2 left_outer_joins
如果您想選擇一組記錄,無論它們是否有關聯的記錄,可以使用left_outer_joins方法。
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
這將產生:
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
這意味著:"返回所有具有評論計數的客戶,無論他們是否有任何評論"。
12.3 where.associated和where.missing
associated和missing查詢方法讓您根據關聯的存在或缺失來選擇一組記錄。
使用where.associated:
Customer.where.associated(:reviews)
產生:
SELECT customers.* FROM customers
INNER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NOT NULL
這意味著“返回至少撰寫了一篇評論的所有客戶”。
使用where.missing:
Customer.where.missing(:reviews)
產生:
SELECT customers.* FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NULL
這意味著“返回沒有撰寫任何評論的所有客戶”。
13 急切加載關聯
急切加載是使用尽可能少的查詢來加載Model.find返回的對象的關聯記錄的機制。
13.1 N + 1 查詢問題
考慮以下代碼,它查找10本書並打印它們的作者姓氏:
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
這段代碼乍看之下沒問題。但問題在於執行的查詢總數。上述代碼總共執行了1次(查找10本書)+ 10次(每本書加載作者)= 11次查詢。
13.1.1 解決 N + 1 查詢問題
Active Record允許您提前指定將要加載的所有關聯。
方法有:
13.2 includes
使用includes,Active Record確保使用最少的查詢加載所有指定的關聯。
使用includes方法重新訪問上述情況,我們可以將Book.limit(10)重寫為急切加載作者:
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上述代碼只會執行2次查詢,而不是原始情況下的11次查詢:
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
13.2.1 急切加載多個關聯
Active Record允許您使用一個Model.find調用的數組、哈希或嵌套的數組/哈希來急切加載任意數量的關聯。
13.2.1.1 多個關聯的數組
Customer.includes(:orders, :reviews)
這將加載所有客戶以及每個客戶的關聯訂單和評論。
13.2.1.2 嵌套關聯哈希
Customer.includes(orders: { books: [:supplier, :author] }).find(1)
這將查找id為1的客戶並急切加載所有關聯的訂單,每個訂單的書籍,以及每本書籍的作者和供應商。
13.2.2 在急切加載的關聯上指定條件
雖然Active Record允許您像joins一樣在急切加載的關聯上指定條件,但建議使用joins代替。
但如果您必須這樣做,可以像平常一樣使用where。
Author.includes(:books).where(books: { out_of_print: true })
這將生成一個包含LEFT OUTER JOIN的查詢,而joins方法將生成一個使用INNER JOIN函數的查詢。
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN books ON books.author_id = authors.id WHERE (books.out_of_print = 1)
如果沒有where條件,這將生成一組正常的兩個查詢。
注意:只有在傳遞給where的是Hash時,才能像這樣使用它。對於SQL片段,您需要使用references來強制連接的表:
Author.includes(:books).where("books.out_of_print = true").references(:books)
在這個includes查詢的情況下,如果任何作者都沒有書籍,所有作者仍然會被加載。通過使用joins(內部連接),連接條件必須匹配,否則不會返回任何記錄。
注意:如果一個關聯作為連接的一部分被急切加載,則自定義選擇子子句中的任何字段將不會出現在加載的模型上。 這是因為不清楚它們應該出現在父記錄還是子記錄上。
13.3 preload
使用preload,Active Record將每個指定的關聯使用一個查詢加載。
重新訪問N + 1查詢問題,我們可以將Book.limit(10)重寫為預加載作者:
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上面的代碼只會執行2個查詢,而不是原始情況下的11個查詢:
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
注意:preload方法使用數組、哈希或數組/哈希的嵌套方式,與includes方法一樣,使用單個Model.find調用來加載任意數量的關聯。然而,與includes方法不同,無法為預加載的關聯指定條件。
13.4 eager_load
使用eager_load,Active Record使用LEFT OUTER JOIN加載所有指定的關聯。
重新訪問N + 1查詢問題的情況下,我們可以將Book.limit(10)重寫為作者:
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上面的代碼只會執行2個查詢,而不是原始情況下的11個查詢:
SELECT DISTINCT books.id FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id LIMIT 10
SELECT books.id AS t0_r0, books.last_name AS t0_r1, ...
FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id
WHERE books.id IN (1,2,3,4,5,6,7,8,9,10)
注意:eager_load方法使用數組、哈希或數組/哈希的嵌套方式,與includes方法一樣,使用單個Model.find調用來加載任意數量的關聯。同樣,像includes方法一樣,您可以為急切加載的關聯指定條件。
13.5 strict_loading
急切加載可以防止N + 1查詢,但您可能仍然會延遲加載一些關聯。為了確保沒有關聯被延遲加載,您可以啟用strict_loading。
通過在關聯上啟用嚴格加載模式,如果記錄嘗試延遲加載關聯,將引發ActiveRecord::StrictLoadingViolationError:
user = User.strict_loading.first
user.comments.to_a # 引發ActiveRecord::StrictLoadingViolationError
14 作用域
作用域允許您指定常用的查詢,可以在關聯對象或模型上引用為方法調用。使用這些作用域,您可以使用之前介紹的每個方法,如where、joins和includes。所有作用域體都應該返回ActiveRecord::Relation或nil,以允許進一步調用它的方法(如其他作用域)。
要定義一個簡單的範圍,我們在類別內使用 scope 方法,傳入我們想要在呼叫此範圍時執行的查詢:
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
要呼叫這個 out_of_print 範圍,我們可以在類別上呼叫它:
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # 所有絕版的書籍
或者在由 Book 物件組成的關聯上呼叫它:
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # `author` 的所有絕版書籍
範圍也可以在範圍內串連:
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
14.1 傳入參數
你的範圍可以接受參數:
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
像呼叫類別方法一樣呼叫範圍:
irb> Book.costs_more_than(100.10)
然而,這只是重複了類別方法所提供的功能。
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
這些方法仍然可以在關聯物件上存取:
irb> author.books.costs_more_than(100.10)
14.2 使用條件
你的範圍可以使用條件:
class Order < ApplicationRecord
scope :created_before, ->(time) { where(created_at: ...time) if time.present? }
end
和其他範例一樣,這將與類別方法類似。
class Order < ApplicationRecord
def self.created_before(time)
where(created_at: ...time) if time.present?
end
end
然而,有一個重要的注意事項:範圍始終會返回一個 ActiveRecord::Relation 物件,即使條件求值為 false,而類別方法則會返回 nil。如果任何條件求值為 false,這可能會導致在串連類別方法時出現 NoMethodError。
14.3 應用預設範圍
如果我們希望一個範圍應用於對模型的所有查詢,我們可以在模型本身內使用 default_scope 方法。
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
當在這個模型上執行查詢時,SQL 查詢將會是這樣的:
SELECT * FROM books WHERE (out_of_print = false)
如果你需要對預設範圍進行更複雜的操作,你可以將它定義為一個類別方法:
class Book < ApplicationRecord
def self.default_scope
# 應該返回一個 ActiveRecord::Relation。
end
end
注意:當以 Hash 格式給定時,default_scope 也會在建立/建構記錄時應用,但不會在更新記錄時應用。例如:
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
請注意,當以 Array 格式給定時,default_scope 查詢參數無法轉換為 Hash 以進行預設屬性分配。例如:
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
14.4 合併範圍
就像where子句一樣,範圍使用AND條件進行合併。
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where(year_published: 50.years.ago.year..) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
我們可以混合使用scope和where條件,最終的SQL將所有條件使用AND連接起來。
irb> Book.in_print.where(price: ...100)
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
如果我們希望最後一個where子句生效,則可以使用merge。
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
一個重要的注意事項是,default_scope將在scope和where條件之前添加。
class Book < ApplicationRecord
default_scope { where(year_published: 50.years.ago.year..) }
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
end
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
如上所示,default_scope在scope和where條件中被合併。
14.5 移除所有範圍
如果出於任何原因希望移除範圍,可以使用unscoped方法。這在模型中指定了default_scope且不應用於特定查詢時特別有用。
Book.unscoped.load
此方法將移除所有範圍並對表執行正常查詢。
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscoped還可以接受一個塊:
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
15 動態查找器
對於您在表中定義的每個字段(也稱為屬性),Active Record都提供了一個查找器方法。例如,如果在您的Customer模型上有一個名為first_name的字段,則可以從Active Record免費獲得find_by_first_name實例方法。如果Customer模型上還有一個locked字段,則還可以獲得find_by_locked方法。
您可以在動態查找器的末尾指定驚嘆號(!),以便在它們不返回任何記錄時引發ActiveRecord::RecordNotFound錯誤,例如Customer.find_by_first_name!("Ryan")。
如果要通過first_name和orders_count進行查找,可以在字段之間簡單地輸入"and"來鏈接這些查找器。例如,Customer.find_by_first_name_and_orders_count("Ryan", 5)。
16 枚舉
枚舉允許您為屬性定義一個值的數組,並通過名稱引用它們。存儲在數據庫中的實際值是映射為其中一個值的整數。
聲明枚舉將:
- 創建可用於查找具有或不具有枚舉值的所有對象的範圍
- 創建可用於確定對象是否具有枚舉的特定值的實例方法
- 創建可用於更改對象的枚舉值的實例方法 對於枚舉(enum)的所有可能值。
例如,給定以下的enum聲明:
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
這些作用域會自動創建,可以用來查找具有特定status值或沒有特定status值的所有對象:
irb> Order.shipped
=> #<ActiveRecord::Relation> # 所有status == :shipped的訂單
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # 所有status != :shipped的訂單
這些實例方法會自動創建,並查詢模型是否具有status枚舉的該值:
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
這些實例方法會自動創建,首先將status的值更新為指定的值,然後查詢狀態是否已成功設置為該值:
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
有關枚舉的完整文檔可以在這裡找到。
17 理解方法鏈
Active Record模式實現了方法鏈,使我們能夠以簡單直觀的方式一起使用多個Active Record方法。
當前一個調用的方法返回一個ActiveRecord::Relation,如all、where和joins時,可以在語句中鏈接方法。返回單個對象的方法(參見檢索單個對象部分)必須位於語句的末尾。
以下是一些示例。本指南不會涵蓋所有可能性,只是舉幾個例子。當調用Active Record方法時,查詢不會立即生成並發送到數據庫。只有在實際需要數據時才會發送查詢。因此,下面的每個示例都生成一個查詢。
17.1 從多個表中檢索過濾的數據
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
結果應該類似於:
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
17.2 從多個表中檢索特定的數據
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
上面的代碼應該生成:
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
注意:如果查詢匹配多條記錄,find_by只會獲取第一條記錄並忽略其他記錄(參見上面的LIMIT 1語句)。
18 查找或創建新對象
通常情況下,您需要查找一個記錄,如果不存在則創建一個新記錄。您可以使用find_or_create_by和find_or_create_by!方法來實現這一點。
18.1 find_or_create_by
find_or_create_by方法檢查是否存在具有指定屬性的記錄。如果不存在,則調用create方法。讓我們看一個例子。
假設您想查找名為"Andy"的客戶,如果沒有,則創建一個。您可以運行以下代碼:
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
這個方法生成的SQL如下所示:
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_by方法返回已存在的記錄或新記錄。在我們的例子中,我們還沒有一個名為Andy的客戶,所以創建並返回了一條記錄。
新記錄可能不會保存到數據庫中;這取決於驗證是否通過(就像create方法一樣)。
假設我們想要在創建新記錄時將“locked”屬性設置為false,但我們不想在查詢中包含它。所以我們想要找到名為“Andy”的客戶,如果該客戶不存在,創建一個名為“Andy”的未鎖定客戶。
我們可以用兩種方式實現。第一種方式是使用create_with:
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
第二種方式是使用塊:
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
該塊只在創建客戶時執行。第二次運行此代碼時,該塊將被忽略。
18.2 find_or_create_by!
您還可以使用find_or_create_by!,如果新記錄無效,則引發異常。本指南不涵蓋驗證,但讓我們暫時假設您在Customer模型中臨時添加了以下驗證:
validates :orders_count, presence: true
如果您嘗試創建一個新的Customer而不傳遞orders_count,則該記錄將無效並引發異常:
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can’t be blank
18.3 find_or_initialize_by
find_or_initialize_by方法的工作方式與find_or_create_by相同,但它將調用new而不是create。這意味著將在內存中創建一個新的模型實例,但不會保存到數據庫。繼續使用find_or_create_by的示例,我們現在想要名為'Nina'的客戶:
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
因為對象尚未存儲在數據庫中,所以生成的SQL如下所示:
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
當您想要將其保存到數據庫時,只需調用save:
irb> nina.save
=> true
19 通過SQL查找
如果您想要在表中使用自己的SQL查找記錄,可以使用find_by_sql。find_by_sql方法將返回一個對象數組,即使底層查詢只返回一條記錄。例如,您可以運行以下查詢:
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sql為您提供了一種簡單的方法來對數據庫進行自定義調用並檢索實例化的對象。
19.1 select_all
find_by_sql有一個相關的方法叫做connection.select_all。select_all會使用自定義的SQL從數據庫中檢索對象,就像find_by_sql一樣,但不會實例化它們。這個方法會返回一個ActiveRecord::Result類的實例,調用to_a方法將返回一個哈希數組,其中每個哈希表示一條記錄。
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
19.2 pluck
pluck可以用來從當前關聯中選取指定列的值。它接受一個列名列表作為參數,並返回指定列的值的數組,數組中的值具有相應的數據類型。
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluck可以替換以下代碼:
Customer.select(:id).map { |c| c.id }
# 或者
Customer.select(:id).map(&:id)
# 或者
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
使用以下代碼:
Customer.pluck(:id)
# 或者
Customer.pluck(:id, :first_name)
與select不同,pluck直接將數據庫結果轉換為Ruby數組,而不構造ActiveRecord對象。對於大型或頻繁運行的查詢,這可能意味著更好的性能。但是,任何模型方法的重寫將不可用。例如:
class Customer < ApplicationRecord
def name
"I am #{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["I am David", "I am Jeremy", "I am Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
您不僅限於從單個表中查詢字段,還可以查詢多個表。
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
此外,與select和其他Relation作用域不同,pluck會立即觸發查詢,因此無法與任何進一步的作用域鏈接,但它可以與先前已構造的作用域一起使用:
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
注意:您還應該知道,如果關聯對象包含include值,使用pluck將觸發急切加載,即使對於查詢來說並不需要急切加載。例如:
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
避免這種情況的一種方法是unscope includes:
irb> assoc.unscope(:includes).pluck(:id)
19.3 pick
pick可以用來從當前關聯中選取指定列的值。它接受一個列名列表作為參數,並返回指定列值的第一行,具有相應的數據類型。
pick是relation.limit(1).pluck(*column_names).first的簡寫形式,當您已經有一個限制為一行的關聯時,它非常有用。
pick可以替換以下代碼:
Customer.where(id: 1).pluck(:id).first
使用以下代碼:
Customer.where(id: 1).pick(:id)
19.4 ids
ids可以用來使用表的主鍵從關聯中選取所有的ID。
irb
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
20 物件的存在性
如果你只是想檢查物件是否存在,可以使用 exists? 方法。
這個方法會使用與 find 相同的查詢來查詢資料庫,但不會返回物件或物件集合,而是返回 true 或 false。
Customer.exists?(1)
exists? 方法也可以接受多個值,但是注意,如果這些記錄中的任何一個存在,它將返回 true。
Customer.exists?(id: [1, 2, 3])
# 或者
Customer.exists?(first_name: ['Jane', 'Sergei'])
甚至可以在模型或關聯上使用 exists? 方法而不帶任何參數。
Customer.where(first_name: 'Ryan').exists?
上面的例子如果至少有一個 first_name 為 'Ryan' 的客戶存在,則返回 true,否則返回 false。
Customer.exists?
上面的例子如果 customers 表是空的,則返回 false,否則返回 true。
你也可以使用 any? 和 many? 在模型或關聯上檢查存在性。many? 會使用 SQL 的 count 方法來確定物件是否存在。
# 通過模型
Order.any?
# SELECT 1 FROM orders LIMIT 1
Order.many?
# SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
# 通過命名範圍
Order.shipped.any?
# SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
# SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
# 通過關聯
Book.where(out_of_print: true).any?
Book.where(out_of_print: true).many?
# 通過關聯
Customer.first.orders.any?
Customer.first.orders.many?
21 計算
本節以 count 方法作為示例,但所描述的選項適用於所有子節。
所有計算方法可以直接在模型上使用:
irb> Customer.count
SELECT COUNT(*) FROM customers
或者在關聯上使用:
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
你也可以在關聯上使用各種查詢方法進行複雜的計算:
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
這將執行以下查詢:
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
假設 Order 有 enum status: [ :shipped, :being_packed, :cancelled ]。
21.1 count
如果你想查看模型表中有多少條記錄,可以調用 Customer.count,它將返回數量。
如果你想更具體地查找所有標題在資料庫中存在的客戶,可以使用 Customer.count(:title)。
有關選項,請參見父節 Calculations。
21.2 average
如果你想查看表中某個數字的平均值,可以在與該表相關的類上調用 average 方法。這個方法調用看起來像這樣:
Order.average("subtotal")
這將返回一個數字(可能是浮點數,例如 3.14159265),表示該字段的平均值。
有關選項,請參見父節 Calculations。
21.3 minimum
如果您想找到表中某个字段的最小值,可以在与该表相关的类上调用minimum方法。方法调用的示例如下:
Order.minimum("subtotal")
有关选项,请参阅父节Calculations。
21.4 maximum
如果您想找到表中某个字段的最大值,可以在与该表相关的类上调用maximum方法。方法调用的示例如下:
Order.maximum("subtotal")
有关选项,请参阅父节Calculations。
21.5 sum
如果您想找到表中所有记录某个字段的总和,可以在与该表相关的类上调用sum方法。方法调用的示例如下:
Order.sum("subtotal")
有关选项,请参阅父节Calculations。
22 运行 EXPLAIN
您可以在关系上运行explain。每个数据库的 EXPLAIN 输出都有所不同。
例如,运行
Customer.where(id: 1).joins(:orders).explain
可能会得到以下结果:
EXPLAIN SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
在 MySQL 和 MariaDB 中。
Active Record 执行了一个漂亮的打印,模拟了相应数据库 shell 的打印。因此,使用 PostgreSQL 适配器运行相同的查询将得到以下结果:
EXPLAIN SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
贪婪加载可能在底层触发多个查询,并且某些查询可能需要先前查询的结果。因此,explain 实际上会执行查询,然后请求查询计划。例如,
Customer.where(id: 1).includes(:orders).explain
在 MySQL 和 MariaDB 中可能会得到以下结果:
EXPLAIN SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
並且可能對於PostgreSQL產生以下結果:
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
22.1 解釋選項
對於支援的資料庫和適配器(目前為PostgreSQL和MySQL),可以傳遞選項以提供更深入的分析。
使用PostgreSQL,以下語句:
Customer.where(id: 1).joins(:orders).explain(:analyze, :verbose)
產生以下結果:
EXPLAIN (ANALYZE, VERBOSE) SELECT "shop_accounts".* FROM "shop_accounts" INNER JOIN "customers" ON "customers"."id" = "shop_accounts"."customer_id" WHERE "shop_accounts"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.30..16.37 rows=1 width=24) (actual time=0.003..0.004 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Inner Unique: true
-> Index Scan using shop_accounts_pkey on public.shop_accounts (cost=0.15..8.17 rows=1 width=24) (actual time=0.003..0.003 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Index Cond: (shop_accounts.id = '1'::bigint)
-> Index Only Scan using customers_pkey on public.customers (cost=0.15..8.17 rows=1 width=8) (never executed)
Output: customers.id
Index Cond: (customers.id = shop_accounts.customer_id)
Heap Fetches: 0
Planning Time: 0.063 ms
Execution Time: 0.011 ms
(12 rows)
使用MySQL或MariaDB,以下語句:
Customer.where(id: 1).joins(:orders).explain(:analyze)
產生以下結果:
ANALYZE SELECT `shop_accounts`.* FROM `shop_accounts` INNER JOIN `customers` ON `customers`.`id` = `shop_accounts`.`customer_id` WHERE `shop_accounts`.`id` = 1
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | r_rows | filtered | r_filtered | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | no matching row in const table |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
1 row in set (0.00 sec)
注意:EXPLAIN和ANALYZE選項在MySQL和MariaDB版本間有所不同。 (MySQL 5.7,MySQL 8.0,MariaDB)
22.2 解釋EXPLAIN
解釋EXPLAIN的輸出超出了本指南的範圍。以下提示可能有所幫助:
SQLite3:EXPLAIN QUERY PLAN
MySQL:EXPLAIN Output Format
MariaDB:EXPLAIN
PostgreSQL:Using EXPLAIN
回饋
歡迎協助提升本指南的品質。
如果您發現任何錯別字或事實錯誤,請貢獻您的力量。 開始之前,您可以閱讀我們的 文件貢獻 部分。
您也可能會發現不完整的內容或過時的資訊。 請為主要的文件補充任何遺漏的內容。請先檢查 Edge 指南,以確認問題是否已經修復或尚未在主分支上修復。 請參考 Ruby on Rails 指南指引 以了解風格和慣例。
如果您發現需要修復但無法自行修補的問題,請 開啟一個問題。
最後但同樣重要的是,關於 Ruby on Rails 文件的任何討論都非常歡迎在 官方 Ruby on Rails 論壇 上進行。